
Redis
Redis简介
Redis介绍
Redis:高性能(运行速度很快,并发很强,跑在内存上)的 NoSql(Not Only SQL) 系列的基于键值的 key-value 数据库
Redis可以当做数据库吗?为什么不能?Redis持久化优势劣势?
Redis 优势
- 性能极高:Redis 能读的速度是 110000 次/s,写的速度是 81000 次/s(查找和操作时间复杂度都是 O1)
- 丰富的数据类型:Redis 支持二进制案例的 string,list,set,zset,hash 数据类型操作
- 原子:Redis 的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过 MULTI 和 EXEC指令包起来
- 丰富的特性:Redis 还支持 publish/subscribe, 通知, key 过期等等特性
相比于如Memcached,为什么要用Redis
- 数据类型:Memcached 所有的值均是简单的字符串;Redis 支持更为丰富的数据类型
- 性能:Redis 的速度比 Memcached 快
- 存储方式:Memecache 把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小;Redis 可以持久化其数据
主流的 NOSQL 产品
- 键值(Key-Value)存储数据库
相关产品: Redis
典型应用: 内容缓存,主要用于处理大量数据的高访问负载。
数据模型: 一系列键值对
优势: 快速查询
劣势: 存储的数据缺少结构化- 列存储数据库
相关产品:HBase
典型应用:分布式的文件系统
数据模型:以列簇式存储,将同一列数据存在一起
优势:查找速度快,可扩展性强,更容易进行分布式扩展
劣势:功能相对局限- 文档型数据库
相关产品:MongoDB
典型应用:Web应用(与Key-Value类似,Value是结构化的)
数据模型: 一系列键值对
优势:数据结构要求不严格
劣势: 查询性能不高,而且缺乏统一的查询语法- 图形(Graph)数据库
相关数据库:Neo4J、InfoGrid、Infinite Graph
典型应用:社交网络
数据模型:图结构
优势:利用图结构相关算法
劣势:需要对整个图做计算才能得出结果,不容易做分布式的集群方案
Redis特点
- Redis的所有操作都是原子的(单线程)
- 速度快,高性能:10WOPS,每秒可实现10W次读写操作(数据存储在内存;C语言精简编写;单线程)
- 支持持久化:Redis所有数据保持在内存中,对数据的更新将异步地保存到磁盘上
- 支持多种数据结构:String;Hash;Linked List;Set;SortedSet
- 多路 IO 复用模型
- 支持多种语言:Java;PHP;Python;Ruby;Lua;Nodejs
- 功能丰富:发布订阅;Lua脚本;事务;pipeline
Redis快的原因
- 用了多路复用 IO 阻塞机制,监听所有 Socket 请求,之后将请求压入队列
IO 多路复用的原理:IO多路复用模型是建立在内核提供的多路分离函数select基础之上,使用select可以避免同步非阻塞 IO 模型中轮询等待- 数据结构简单,操作节省时间
- 运行在内存中,自然速度快
- 单线程避免了多线程频繁上下文切换
Redis是单线程,主要是指原来处理用户命令的线程是单线程。Redis在4.0之后,就引入了多线程,比如说除了处理用户命令的主线程之外,还会起异步的线程去做一些资源释放,清理脏数据,删除大key等工作
Redis数据类型
- 字符串类型 String
- 哈希类型 Hash:Map格式
- 列表类型 List:LinkedList格式,支持重复元素
- 集合类型 Set:不允许重复元素
- 有序集合类型 SortedSet:元素有顺序,但不允许重复元素
Redis应用场景
- 缓存(数据查询、短连接、新闻内容、商品内容等等)
- 聊天室的在线好友列表
- 任务队列(秒杀、抢购、12306等等)
- 应用排行榜
- 网站访问统计
- 数据过期处理(可以精确到毫秒)
- 分布式集群架构中的Session分离
Redis线程模型
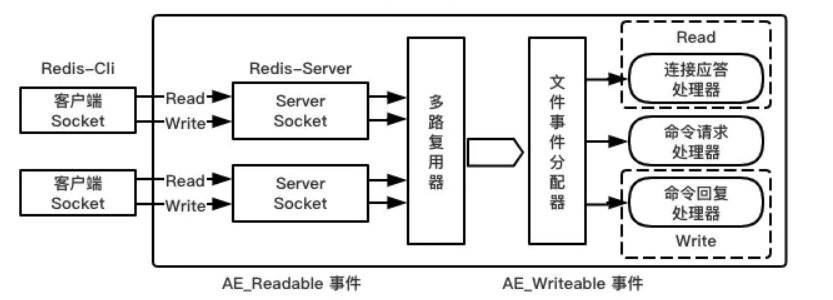
Redis基于Reactor模式开发了网络事件处理器,这个处理器叫做文件事件处理器file event handler。这个文件事件处理器,它是单线程的,所以Redis 才叫做单线程的模型,它采用IO多路复用机制来同时监听多个Socket,根据Socket上的事件类型来选择对应的事件处理器来处理这个事件。可以实现高性能的网络通信模型,又可以跟内部其他单线程的模块进行对接,保证了Redis内部的线程模型的简单性。
文件事件处理器的结构包含4个部分:多个Socket、I0多路复用程序、文件事件分派器以及事件处理器(命令请求处理器、命令回复处理器、连接应答处理器等)。
多个Socket可能并发的产生不同的操作,每个操作对应不同的文件事件,但是I0多路复用程序会监听多个Socket,会将Socket放入一个队列中排队,每次从队列中取出一个Socket 给事件分派器,事件分派器把Socket给对应的事件处理器。
然后一个Socket的事件处理完之后,I0多路复用程序才会将队列中的下一个Socket给事件分派器。文件事件分派器会根据每个Socket当前产生的事件,来选择对应的事件处理器来处理。
每一条到达服务端的命令都不会立即执行,所有命令都会进入一个队列中,所以Redis不会产生并发问题
Redis 6.0版本前的单线程模型
Redis的核心网络模型选择用单线程来实现。正如redis官网上说,对于一个 DB 来说,CPU 通常不会是瓶颈,因为大多数请求不会是 CPU 密集型的,而是 I/O 密集型。具体到 Redis 的话,如果不考虑 RDB/AOF 等持久化方案,Redis 是完全的纯内存操作,执行速度是非常快的,因此这部分操作通常不会是性能瓶颈,Redis 真正的性能瓶颈在于网络 I/O,也就是客户端和服务端之间的网络传输延迟,因此 Redis 6.0版本前选择了单线程的 I/O 多路复用来实现它的核心网络模型
使用单线程网络模型好处:
- 避免过多的上下文切换开销:多线程调度过程中必然需要在 CPU 之间切换线程上下文 context,而上下文的切换是有开销的。单线程则可以规避进程内频繁的线程切换开销,因为程序始终运行在进程中单个线程内,没有多线程切换的场景
- 避免同步机制的开销:如果 Redis 选择多线程模型,势必涉及到底层数据同步的问题,必然会引入某些同步机制,比如锁,而我们知道 Redis 不仅仅提供了简单的 key-value 数据结构,还有 list、set 和 hash 等等其他丰富的数据结构,而不同的数据结构对同步访问的加锁粒度又不尽相同,可能会导致在操作数据过程中带来很多加锁解锁的开销,增加程序复杂度的同时还会降低性能
单 Reactor 模型:利用 epoll/select/kqueue 等多路复用技术,在单线程的事件循环中不断去处理事件(客户端请求),最后回写响应数据到客户端
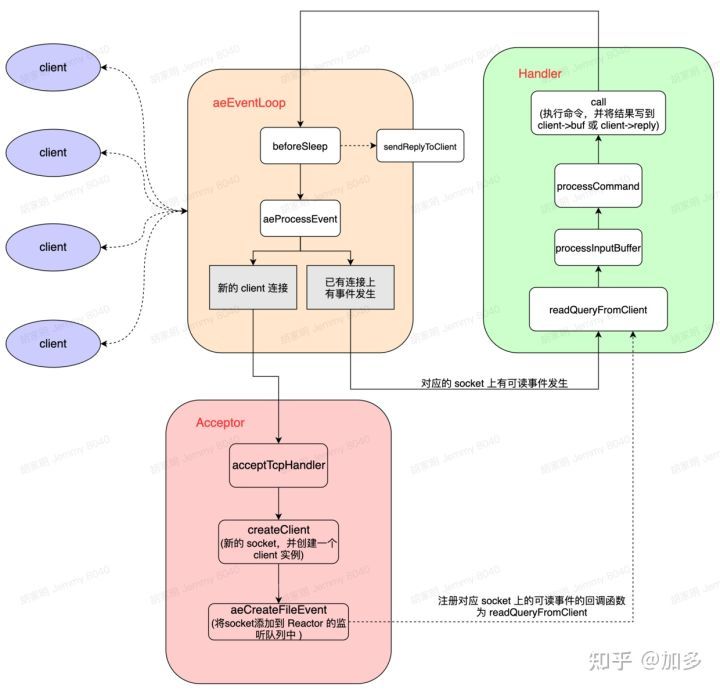
- aeEventLoop:这是 Redis 自己实现的一个高性能事件库,里面封装了适配各个系统的 I/O多路复用(I/O
multiplexing),EventLoop除了 处理socket的读写事件外,还要处理一些定时任务。aeEventLoop本质是一个线程,服务启动时就一直循环,调用 aeProcessEvent 处理文件(网络)或者时间事件;等价于Java中NIO的select线程 - client :代表一个客户端连接。Redis 是典型的 CS 架构(Client <---> Server),客户端通过
socket 与服务端建立网络通道然后发送请求命令,服务端执行请求的命令并回复。Redis 使用结构体 client存储客户端的所有相关信息,包括但不限于封装的套接字连接 – conn,当前选择的数据库指针 – db,读入缓冲区 – querybuf,写出缓冲区 – buf,写出数据链表 – reply等 - acceptTcpHandler:角色 Acceptor 的实现,当有新的客户端连接时会调用这个方法,它会调用系统 accept 创建一个socket 对象,同时创建 client 对象,并将 socket 添加到 EventLoop的监听列表中(等价于NIO中注册socket到select上),并注册当对应的读事件发生时的回调函数 readQueryFromClient:即绑定 Handler,这样当该客户端发起请求时,就会调用对应的回调函数处理请求
- readQueryFromClient:角色 Handler 的实现,主要负责解析并执行客户端的命令请求,并将结果写到对应的 client->buf 或者 client->reply 中
- beforeSleep:事件循环之前的操作,主要执行一些常规任务,比如将 client 中的数据写会给客户端、进行一些持久化任务(AOF 或者RDB操作,主从同步)等
工作过程:
- Redis 服务器启动,开启主线程事件循环 aeMain,注册 acceptTcpHandler 连接应答处理器到用户配置的监听端口对应的文件描述符,等待新连接到来
- 客户端和服务端建立网络连接,acceptTcpHandler 被调用,主线程将 readQueryFromClient 命令读取处理器绑定到新连接对应的文件描述符上作为对应事件发生时的回调函数,并初始化一个 client 绑定这个客户端连接
- 客户端发送请求命令,触发读就绪事件,主线程调用 readQueryFromClient 通过 socket 读取客户端发送过来的命令存入 client->querybuf 读入缓冲区
- 接着调用 processInputBuffer,在其中使用 processInlineBuffer 或者 processMultibulkBuffer 根据 Redis 协议解析命令,最后调用 processCommand 执行命令
- 根据请求命令的类型(SET, GET, DEL, EXEC 等),分配相应的命令执行器去执行,最后调用 addReply
函数族的一系列函数将响应数据写入到对应 client 的写出缓冲区:client->buf 或者 client->reply
,client->buf 是首选的写出缓冲区,固定大小
16KB,一般来说可以缓冲足够多的响应数据,但是如果客户端在时间窗口内需要响应的数据非常大,那么则会自动切换到
client->reply链表上去,使用链表理论上能够保存无限大的数据(受限于机器的物理内存),最后把 client 添加进一个 LIFO
队列 clients_pending_write - 在事件循环 aeMain 中,主线程执行 beforeSleep --> handleClientsWithPendingWrites,遍历 clients_pending_write 队列,调用writeToClient 把 client 的写出缓冲区里的数据回写到客户端,如果写出缓冲区还有数据遗留,则注册sendReplyToClient 命令回复处理器到该连接的写就绪事件,等待客户端可写时在事件循环中再继续回写残余的响应数据
Redis 6.0版本后的多线程模型
多个线程(IO Thread)各自维护一个独立的事件循环。整体模型是由 Main 线程负责接收新连接,并分发给 IO Thread 去独立处理(解析请求命令),但是具体命令的执行还是使用main 线程来执行,最后使用IO 线程回写响应给客户端。IO线程轮训socket列表读事件,然后解析为redis命令,并把解析好的命令放到全局待执行队列,然后主线程从全局待执行队列读取命令然后具体执行命令,最后把响应结果分配到不同IO线程,由IO线程来具体执行把响应结果写回客户端。具体命令执行还是由main线程所在的事件循环单线程处理,只是读写socket事件由IO线程来处理
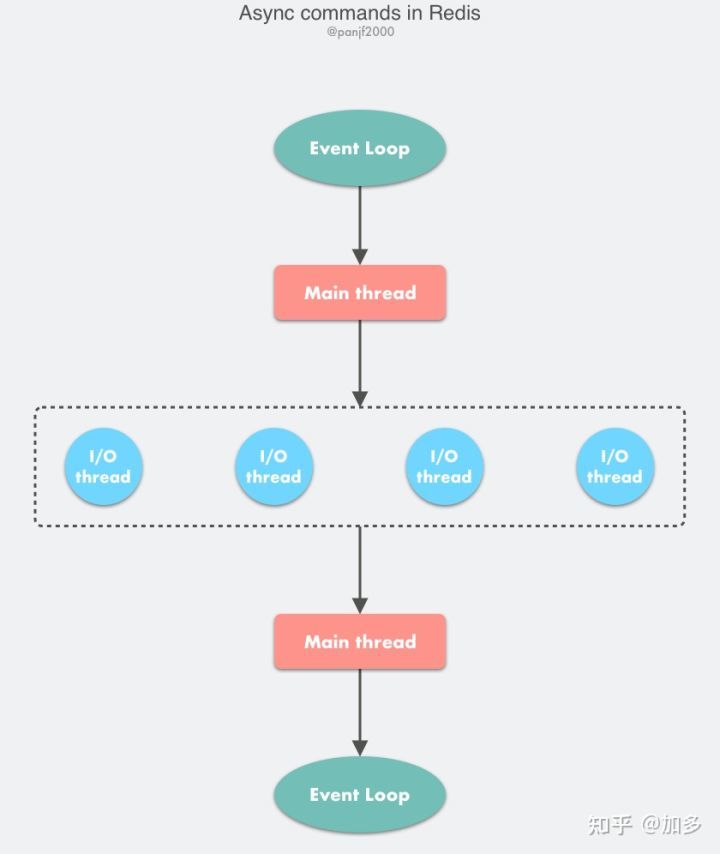
工作过程:
- 首先所有命令的执行仍然在主线程中进行,仍然存在性能瓶颈
- 另外IO 读写为批处理读写,即所有 IO 线程先读取完请求数据并且解析为redis命令后,主线程才开始执行解析的命令;然后待主线程执行完所有的redis命令后,才让所有 IO 线程再一起回复所有响应;也就是说不同请求需要相互等待,效率不高
- 最后在 IO 批处理读写和主线程处理时,使用线程自旋检测等待(如下代码),效率更是低下,即便任务很少,也很容易把 CPU 打满
Redis安装
Windows10
官网:https://redis.io/
中文:http://www.redis.net.cn/
解压:
redis.windows.conf:配置文件
redis-cli.exe :客户端
redis-server.exe :服务器端
CentOS 7
安装:
tar -xzf redis-3.0.7.tar.gz
ln -s redis-3.0.7 redis
cd redis
make && make install
redis-server启动:
最简启动:redis-server (默认配置)
动态参数:redis-server --port 6380
配置文件:redis-server configPath
在redis目录下创建config目录,并把redis.conf复制到config目录下,更名为redis-6381.conf
去掉conf文件的注释:cat redis-6381.conf | grep -v "#" | grep -v "^$" > redis-6381-hefery.conf
编辑redis-6381-hefery.conf
启动:在redis路径下
redis-server redis-6381-hefery.conf
redis-cli客户端:
连接:redis-cli -h 127.0.0.1 -p 7000 -a 123456
退出:quit
关闭:
停止redis-server服务: redis-server &
redis-cli -p 6379 shutdown
查看启动:
ps -ef | grep redis
ps aux | grep redis
Windows连接Linux Redis:
关闭防火墙:systemctl stop firewalld
redis.conf设置bind 0.0.0.0
怎么测试 Redis 的连通性?
使用 ping 命令
Redis数据类型
Redis的数据结构:Redis 存储的是 key:value 格式的数据,其中key都是字符串,value有不同的数据结构
一个 Redis 实例最多能存放多少的 keys?
理论上 Redis 可以处理多达 232 的 keys,并且在实际中进行了测试,每个实例至少存放了 2 亿 5 千万的 keys。我们正在测试一些较大的值。任何 list、set、和 sorted set 都可以放 232 个元素。换句话说,Redis 的存储极限是系统中的可用内存值
基本数据类型
字符类型 string
结构
key : value
底层数据结构:整型int + embstr编码的简单动态字符串 + raw编码的简单动态字符串
场景
-
缓存:热点数据、对象缓存、全页缓存
- 单值缓存:
set key value
get key - 对象缓存:
set user:1 value(JSON数据)
mset user:1:name hefery user:1:age 23
mget user:1:name user:1:age - 分布式锁:
setnx product:10001 true // 1-获取锁成功 0-获取锁失败 ... // 业务操作 del product:10001 // 释放锁 set product:10001 true ex 10 nx // 防止程序以外终止导致死锁
- 单值缓存:
-
计数器:个人主页的访问量(incr userid:pageview)
incr article:readcount:{article_id}
get article:readcount:{article_id} -
分布式系统全局序列号:
incrby order_id 100// Redis批量生成序列号提升性能 -
数据共享:spring-session-data-redis
API
- 设置:
不管key是否存在:set key value
key不存在才设置:setnx key value
key要存在才设置:set key value xx
批量设置key:mset key1 key2...
设置新值返回旧值:getset key newvalue
value追加:append key value
设置字符串指定下标的所有值:setrange key index value
设置过期时间:expire key second - 获取:
单个获取:get key
批量获取:mget key1 key2...
字符串长度:strlen key(一个中文两个字节)
字符串指定下标的所有值:getrange key stsrt end(index从0开始) - 删除:
del key - 自增:
整数自增:incr key(自增1)、incrby key 66(自增66)
浮点自增:incrbyfloat key 6.6(自增6.6) - 自减:
整数自减:decr key(自减1)、decrby key 66(自减66)
浮点自减:decrbyfloat key 6.6(自减6.6)
string底层、zset的底层
一个字符串类型的值能存储最大容量是多少?512M
哈希类型 hash
结构
key : field-value
底层数据结构:哈希表HashTable + 压缩表Ziplist
场景
- 缓存
hmst user {user_id}:name hefery {user_id}:age 23hmst user 1:name hefery 1:age 23
hmget user 1:name 1:age - 计数器:个人主页的访问量(hincrby user:1:info pageview count)(incr)
电商:key : field-value 用户ID:商品ID-商品数量
购物车:
添加商品:`hset cart:1001 10088 1`
增加数量:`hincrby cart:1001 10088 1`
商品总数:`hlen cart:1001 10088`
获取购物车所有商品:`hgetall cart:1001`
排行榜:新闻ID=6001
新闻点击数+1:zincrby hotNews:20211111 1 n6001
今天点击最多:zrevrange hotNews:20211111 0 1 withscores
API
- 设置:
设置hash key对应field的value:hsetnx key field value(如果field已存在则失败)
设置hash key filed的value:hset key field value
批量设置hash key filed的value:hmset key1 key2... - 获取:
获取hash key filed的value:hget key field
批量hash key filed的value:hmget key1 key2...
获取所有hash key对应的key-filed的value:hgetall key
获取所有hashkey对应的field:hkeys key
获取所有hash key对应的filed的value:hvals key
获取hash key field数量:hlen key - 删除:
删除hash key filed:hdel key field - 自增:
整数自增:hincr key field(自增1)、hincr key field 66(自增66)
浮点自增:hincrbyfloat key field 6.6(自增6.6) - 自减:
整数自减:hdecrby key field(自减1)、hdecrby key field 66(自减66)
浮点自减:hdecrbyfloat key field 6.6(自减6.6) - 判断:
判断hash key是否存在field:hexists key field
Redis哈希表和Java哈希表区别?具体说说扩容区别?
- Redis中的rehash;Java中的resize
- Redis的有缩容,Java的没有,而且具体的过程也有所不同
Redis中的扩容不是一次完成的,可以分多次,是渐进式地,而Java的是一次完成的
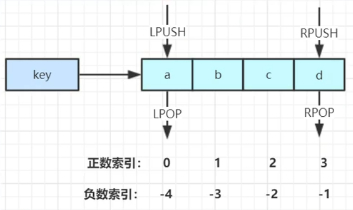
列表类型 list
结构
key : elements(有序;可重)
底层数据结构:双端链表LinkedList + 压缩表Ziplist
场景
- 用户消息时间线timeline:双向链表,插入有序
- 消息队列:blpop、brpop,可设置超时时间
- 栈Stack:先进后出 lpush + lpop
- 队列Queue:右头左尾,左进右出 lpush + rpop
- 阻塞队列Blocking MQ:lpush + brpop
API
- 设置:
从右向list插入值:rpush key value1 value2...
从左向list插入值:lpush key value1 value2...
在list指定的value值前或后插入newvalue:linsert key before|after value newvalue
设置list指定index的item为newvalue:lset key index newvalue - 弹出:
从list左侧弹出item:lpop key
从list右侧弹出item:rpop key
根据count的值弹出所有value相等的item:lrem key count value
count > 0:从左到右,弹出最多count个value相等的item
count < 0:从右到左,弹出最多Mash.abs(count)个value相等的item
count = 0:删除所有value相等的item
按照index范围修剪list:itrim key start end
lpop阻塞版本:blpop key timeout(timeout为超时时间,为0即永不阻塞)
rpop阻塞版本:brpop key timeout(timeout为超时时间,为0即永不阻塞) - 获取:
获取list的(start, end]的所有item:lrange key start end
PS:a b c d e f:index从左到右-0~5,从右到左-1~-6
获取list指定index的item:lindex key index
获取list长度:llen key
集合类型 set
结构
key : values(无序;无重)
底层数据结构:整型集合intset + 哈希表HashTable
场景
- 抽奖
点击参与抽奖加入集合:sadd key {user_id}
查看参与抽奖所有用户:smembers key
抽取count名中奖者:srandmember key count/spop key count - 微博:
- 点赞:微博ID=t1001、用户ID=u3001、点赞用户:like:t1001来维护所有为这条微博点赞的用户
微博点赞:sadd like:微博ID_1001 用户ID_3001
取消点赞:srem like:微博ID_1001 用户ID_3001
是否点赞:sismember like:微博ID_1001 用户ID_3001
点赞列表:smember like:微博ID_1001 用户ID_3001
点赞数量:scard like:微博ID_1001 - 关注:用户关注:
follow 关注 fans 粉丝
相互关注:sadd 1:follow 2; sadd 2:fans 1; sadd 1:fans 2; sadd 2:follow 1
共同关注:我关注的人也关注她,交集sinter hefery lalala
我可能认识的人:差集sdiff hefery lalala
我关注的人也关注他:sismember hefery lalala
- 点赞:微博ID=t1001、用户ID=u3001、点赞用户:like:t1001来维护所有为这条微博点赞的用户
API
- 添加:
添加value:sadd key value1 value2...(如果value已存在则失败) - 删除:
删除value:srem key value
从set随机弹出一个元素:spop key - 获取:
获取set大小:scard key
从set随机挑选count个元素,不删除:srandmember key count
从set随机挑选count个元素,要删除:spop key count
获取set所有value:smembers key - 判断:
判断value是否在set中:sismember key// 1-存在 - 集合间的操作:
差集:sdiff key1 key2
交集:sinter key1 key2(共同关注)
并集:sunion key1 key2
有序集合 sortedset
结构
key : [score-value](有序;无重)
底层数据结构:跳表Skiplist + 压缩表Ziplist
场景
- 排行榜
API
- 添加:
添加score-value:zadd key score value(score可重,value不重) - 删除:
删除score-value:zrem key value
删除指定排名的升序元素:zremrangebtrank key stsrt end
删除指定分数范围内的升序元素:zremrangebyscore key minscore maxscore - 获取:
获取value的score:zscore key value
增加或减少value的score:zincrby key increscore value
获取集合元素个数:zcard key
获取指定范围(按score升序)内元素:zrange key start end
获取指定分数范围内的升序元素:zrangebyscore key minscore maxscore
zrevrank
zrevrange
zrevrangebyscore - 集合:
并集:zunionstore destkey numkeys key1 key2...
交集:zinterstore destkey numkeys key1 key2...
通用命令
keys:
所有的key:keys *
key得数量:dbsize
key的正则:keys [pattern]
exists:
检查key是否存在:exists key
del:
删除指定的key-value:del key1 key2...
expire:
设置key的过期时间:expire key seconds
查看key的剩余时间:ttl key(-2代表key已经不存在)
去掉key的过期时间:persist key((-1代表key存在,并且没有过期时间)
type:
查看key的类型:type key(string、hash、list、set、zset、none)
其他数据结构
BitMap
位图:二进制
API:
给位图指定索引设置值:setbit key offset value
获取位图指定范围(start到end,单位字节,如果不指定就获取全部)位值为1的个数:bitcount key [start end]
计算位图指定范围(start到end,单位字节,如果不指定就获取全部)第一个偏移量对应的值等于targetBit的位置:bitpos key targetBit [start] [end]
HperLogLog
基于HyperLogLog算法:极小空间完成独立数量统计
API:
向hyperloglog添加元素:fadd key element1 element2...
计算hyperloglog的独立总数:pfcount key1 key2...
合并多个 hyperloglog:pfmerge destkey sourcekey1 sourcekey2…
GEO
GEO(地理信息定位):存储经纬度,计算两地距离,范围计算等
API:
增加地理位置信息:geo key longitude latitude member [longitude latitude member]
获取地理位置信息:geopos key member [member]
获取两个地理位置的距离:geodist key memberl member2 [unit] unit:m(米)、km(千米)、mi(英里)、ft(尺)
获取指定位置范围内的地理位置信息集合:
georadius key longitude latitude radium|km|ft|mi
[withcoord] :返回结果中包含经纬度
[withdist] :返回结果中包含距离中心节点位置
[withhash] :返回结果中包含 geohash COUNT count:指定返回结果的数量
[COUNT count]:指定返回结果数量
[asc|desc] :返回结果按照距离中心节点的距离做升序或者降序
[store key] :将返回结果的地理位置信息保存到指定键
[storedist key]:将返回结果距离中心节点的距离保存到指定键
georadiusbymember key member radium|km|ft|mi
[withcoord] :返回结果中包含经纬度
[withdist] :返回结果中包含距离中心节点位置
[withhash] :返回结果中包含 geohash COUNT count:指定返回结果的数量
[COUNT count]:指定返回结果数量
[asc|desc] :返回结果按照距离中心节点的距离做升序或者降序
[store key] :将返回结果的地理位置信息保存到指定键
[storedist key]:将返回结果距离中心节点的距离保存到指定键
Redis客户端
Jedis
Redis的java客户端
| Jedis配置参数 | 参数含义 | 默认 | 建议 |
|---|---|---|---|
| 资源数控制 | |||
| maxTotal | 资源池最大连接数 | 8 | 后面讨论 |
| maxIdle | 资源池允许最大空闲连接数 | 8 | 建议maxTotal |
| minIdle | 资源池允许最小空闲连接数0 | 后面讨论 | |
| jmxEnabled | 是否开启jmx监控 | true | 建议开启 |
| 借还参数 | |||
| blockWhenExhausted | 当资源池用尽后,调用者是否要等待。当为true时,maxWaitMillis才生效 | true | 建议使用默认值 |
| maxWaitMillis | 当资源池连接用尽后,调用者的最大等待时间(单位为毫秒) | -1:永不超时 | 不建议使用默认值 |
| testOnBorrow | 向资源池借用连接时是否做连接有效性检测(ping),无效连接会被移除 | false | 建议false |
| testOnReturn | 向资源池归还连接时是否做连接有效性检测(ping),无效连接会被移除 | false | 建议false |
maxTotal:根据业务而定
命令平均执行时间0.1ms=0.001s;业务需要5w QPS;maxTotal理论值=0.001*5w=50,实际值需要更大
业务希望Redis并发量;客户端执行命令时间;Redis资源(应用个数Nodes * maxTotal <= Redis最大连接数maxclients)
maxIdle:建议maxIdle=maxTotal
减少创建新连接的开销
maxIdle:建议预热maxIdle
减少第一次启动后的新连接开销
获取超时:
原因:
慢查询阻塞,连接池被堵住
资源池参数配置不合理(QPS高,连接池容量小)
连接泄露(没有close,比较难定位)
Redis功能
慢查询
慢查询发生在Redis执行命令阶段
配置:
slowlog-max-len:
默认128(先进先出的队列 + 固定长度 + 保存在内存)
不要设置过大,默认10ms,通常设置1ms
slowlog-log-slower-than:默认1w
1. 慢查询阈值(单位:微秒)
2. slowing-log- slower-than=0,记录所有命令
3. slowing-og- slower-than<0,不记录任何命令
sawlog-log- slower-than不要设置过小,通常设置1000左右
动态配置:
config set slowlog-max-len 1000
config set slowing-og- slower-than 1000
API:
获取慢查询队列:slowlog get [n]
获取慢查询队列长度:slowlog len
清空慢查询队列:slowlog reset
流水线Pipeline
Redis执行命令都是微妙级别
pipeline每次条数要控制(网络)
注意每次 pipeline携带数据量
pipeline每次只能作用在一个 Redis节点上
| 命令 | N个命令操作 | 1次pipeline(n个命令) |
|---|---|---|
| 时间 | n次网络传输时间+n次命令执行时间 | 1次网络传输时间+1次命令执行时间 |
| 数据量 | 1条命令 | n条命令 |
发布订阅
角色:
发布者publisher:
订阅者subscriber:
频道channel:
模型:
发布者(redis-cli-publisher) -> Sohutv频道(redis-server) -> 订阅者(redis-cli-subscriber)
API:
发布消息:publish channel message
订阅消息:subscribe [channel(n)]
取消订阅:unsubscribe [channel(n)]
Redis发布订阅和直接用List区别
Redis发布订阅和消息中间件区别
Redis事务
Redis事务就是一次性、顺序性(先进先出FIFO)、排他性的执行一个队列中的一系列命令
特点:
- Redis事务没有隔离级别:批量操作在发送 EXEC 命令前被放入队列缓存,并不会被实际执行,也就不存在事务内的查询要看到事务里的更新,事务外查询不能看到
- Redis不保证原子性:Redis中单条命令是原子性执行,不保证原子性,且不支持回滚。事务中任意命令执行失败,其余的命令仍会被执行
- 事务在执行过程中不会被中断,当事务队列中的所有命令都被执行完毕之后,事务才会结束
Redis为什么不支持回滚:在事务运行期间,虽然Redis命令可能会执行失败,但是Redis仍然会执行事务中余下的其他命令,而不会执行回滚操作,你可能会觉得这种行为很奇怪。然而,这种行为也有其合理之处:只有当被调用的Redis命令有语法错误时,这条命令才会执行失败(在将这个命令放入事务队列期间,Redis能够发现此类问题),或者对某个键执行不符合其数据类型的操作:实际上,这就意味着只有程序错误才会导致Redis命令执行失败,这种错误很有可能在程序开发期间发现,一般很少在生产环境发现。 Redis已经在系统内部进行功能简化,这样可以确保更快的运行速度,因为Redis不需要事务回滚的能力。对于Redis事务的这种行为,有一个普遍的反对观点,那就是程序有可能会有缺陷(bug)。但是,你应当注意到:事务回滚并不能解决任何程序错误。例如,如果某个查询会将一个键的值递增2,而不是1,或者递增错误的键,那么事务回滚机制是没有办法解决这些程序的问题
事务三阶段:
- 开始事务:multi
- 命令入队:set、get
- 监控key:watch
- 取消watch:unwatch
- 执行事务:exec
Redis持久化
基本上会使用 AOF 作为 Redis 持久化方案
RDB
RDB:Redis DataBase将某一时刻的内存快照以二进制的方式写入磁盘。实际的操作过程是 fork() 一个字进程,先将数据集写入临时文件,再替换之前的文件,用二进制进行压缩
优点:
- 方便持久化:只包含一个 dump.rdb 文件
- 容灾性好,方便备份
- 性能最大化:通过异步操作实现,fork子进程完成写操作,主线程继续处理命令(IO最大化)
缺点:
- 数据安全性低:RDB是间隔执行,如果RDB持久化过程中,Redis发生故障,会丢失数据
- 数据集较大时,对性能不太友好
持久化方式:RDB:拍快照、AOF:写日志
1.RDB:默认方式,不需要进行配置
在一定的间隔时间中,检测key的变化情况,保存某个时间点的全量数据,然后持久化数据
1.编辑redis.windwos.conf文件
# after 900 sec (15 min) if at least 1 key changed
save 900 1
# after 300 sec (5 min) if at least 10 keys changed
save 300 10
# after 60 sec if at least 10000 keys changed
save 60 10000
2.重新启动redis服务器,并指定配置文件名称
W:\JAVA\Redis\redis\windows-64\redis-2.8.9>redis-server.exe redis.windows.conf
2.AOF:日志记录的方式,可以记录每一条命令的操作。可以每一次命令操作后,持久化数据
1. 编辑redis.windwos.conf文件
appendonly no(关闭aof) --> appendonly yes (开启aof)
# appendfsync always : 每一次操作都进行持久化
appendfsync everysec : 每隔一秒进行一次持久化
# appendfsync no : 不进行持久化
3.RDB-AOF混合:BGSave全量持久化,AOF增量持久化
| API | RDB | AOF |
|---|---|---|
| 启动优先级 | 低 | 高 |
| 体积 | 小 | 大 |
| 恢复速度 | 快 | 慢 |
| 数据安全 | 丢数据 | 策略决定 |
| 轻重 | 重 | 轻 |
触发机制:
save(同步):通常会阻塞Redis
redis-cli执行save命令,redis-sever创建RDB二进制文件(新的文件替换旧文件)
bgsave(异步):不会阻塞Redis,但会fork新进程
redis-cli执行bgsave命令,redis-sever执行fork(),创建子进程完成创建RDB二进制文件(新的文件替换旧文件)
自动:
#save 900 1
#save 300 10
#save 60 10000
dbfilename dump-${port}.rdb # RDB文件名
dir /bigdiskpath
stop-writes-on-bgsave-error yes # 报错,终止bgsave
rdbcompression yes
rdbchecksum yes
复制方式:
全量复制:
debug reload:
shutdown:
RDB问题:
耗时-O(n);耗性能-fork()消耗内存;Disk IO-IO性能
不可控,丢失数据
| API | save | bgsave |
|---|---|---|
| IO类型 | 同步 | 异步 |
| 阻塞 | 阻塞 | 阻塞(fork阶段) |
| 复杂度 | O(n) | O(n) |
| 优点 | 不会消耗额外内存 | 不阻塞客户端命令 |
| 缺点 | 阻塞客户端命令 | 需要fork,消耗内存 |
AOF
AOF:以日志形式(文本)记录 Redis 处理的命令(查询除外)
优点:
- 数据安全:同步策略包含每秒同步、每修改同步、不同步
- 通过 append 模式写文件:即使 Redis 发生故障也不会破坏日志内容,可以通过 redis-check-aof 工具解决数据一致性
- rewrite 模式定期对 AOF 文件进行重写
缺点:
- AOF 文件比 RDB 文件大,恢复速度慢
- 数据集大时,启动效率低
触发机制:
always:
redis-cli写命令刷新缓冲区,缓冲区中每条命令fync到硬盘的AOF文件
everysec:
redis-cli写命令刷新缓冲区,每秒把缓冲区fync到硬盘的AOF文件
no:
redis-cli写命令刷新缓冲区,OS决定缓冲区中命令fync到硬盘的AOF文件
AOF重写:
重写:
set hello world; set hello java; -> set hello java
incr counter; incr counter; -> set counter 2
作用:减少硬盘占用量;加速恢复速度
操作:
redis-cli执行bgrewriteaof,redis-sever执行fork(),创建子进程实现AOF重写
配置:
auto-aof-rewrite-min-size # AOF文件重写需要的尺寸
auto-aof-rewrite-percentage # AOF文件增长率
aof_current_size # AOF当前尺寸(单位:字节)
aof-base-size # AOF上次启动和重写的尺寸(单位:字节)
------------------------------------------------------------------
appendonly yes
appendfilename “appendonly-${port}.aof”
appendfsync everysec
dir /bigdiskpath
no-appendfsync-on-rewrite yes
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
自动:同时满足
aof_current_size > auto-aof-rewrite-min-size
(aof_current_size - aof-base-size) | (aof-base-size > auto-aof-rewrite-percentage)
| API | always | everysec | no |
|---|---|---|---|
| 优点 | 不丢失数据 | 每秒一次fsync,丢1s数据 | 不用 |
| 缺点 | IO开销大 | 丢1s数据 | 不可控 |
开发运维问题
fork操作
特点:
1. 同步操作:比较快
2. 与内存量息息相关:内存越大,耗时越长(与机型相关)
3. 查看fork info:latest_fork_usec
改善:
优先使用物理机或高效支持fork操作的虚拟化技术
控制Redis实例最大可用内存Lmaxmemory
合理配置Linux内存分配策略:vm.overcommit_memory=1
降低fork频率:放宽AOF重写自动触发时机,不必要全量复制
子进程开销和优化
1.CPU
开销:RDB和AOF文件生成,属于CPU密集型
优化:不做CPU绑定,不和CPU密集型应用部署
2.内存
开销:fork内存开销,copy-on-write会开一个副本
优化:echo never > /sys/kernel/mm/transparent_hugepage/enabled
3.硬盘
开销:AOF和RDB文件写入,iostat、iotop分析
优化:
不要和高硬盘负载服务(存储服务、消息队列)部署在一起
no-appendfsync-on-write=yes
根据写入量决定磁盘类型:ssd
单机多实例持久化文件目录考虑分盘
AOF追加阻塞
流程:
主线程写入到AOF缓冲区,每秒同步到硬盘,对比上次fsync时间(大于2s-阻塞;小于2s-通过)
定位:
Redis日志:Asynchronous AOF fsync is taking too long(disk is busy?)
命令info persistence:aof_delayed_fsync:100
Redis集群
Redis主从模式
在主从复制中,数据库分为主库(master)和从库(slave)
特点:
- 主库master进行写操作导致数据变化时会自动将数据同步给从数据库
- 从库slave接收主库master同步过来的数据,进行读操作
- 一个master可以拥有多个slave,但一个slave只能对应一个master
- slave挂了不影响其他slave的读和master的读和写,重新启动后会将数据从master同步过来
- master挂了以后,不会在slave节点中重新选一个master,也不影响slave的读,但Redis不再提供写服务,master重启后将重新对外提供写服务
问题:
- 机器故障:不具备高可用性,当 master 挂掉以后,Redis将不能再对外提供写入操作
- 容量瓶颈:
- QPS瓶颈:
作用:数据副本;拓展读性能
主从原理:当 slave 启动后,主动向 master 发送 SYNC 命令。master 接收到 SYNC 命令后在后台保存快照(RDB持久化)和缓存保存快照这段时间的命令,然后将保存的快照文件和缓存的命令发送给 slave。slave 接收到快照文件和命令后加载快照文件和缓存的执行命令。复制初始化后,master 每次接收到的写命令都会同步发送给 slave,保证主从数据一致性
主从复制集群的搭建
实现:
salveoof:无需重启
复制:redis-cli执行salveoof 127.0.0.1 6379命令,redis-cli-slave(6380)复制给redis-cli-master(6379)
取消:redis-cli执行salveoof no one命令,redis-cli-slave(6380)取消复制给redis-cli-master(6379)
配置:统一配置,需要重启
slaveof ip port
slave-read-only yes
# redis-master-6379.conf
daemonize yes
pidfile /var/run/redis-master-6379.pid
port 6379
logfile "master-6379.log"
#save 900 1
#save 300 10
#save 60 10000
dbfilename dump-master-6379.rdb
dir /home/hefery/Downloads/Redis/redis/data/log
appendonly yes
appendfilename "appendonly-master-6379.aof"
# redis-slave-6380.conf
daemonize yes
pidfile /var/run/redis-slave-6380.pid
port 6380
logfile "slave-6380.log"
#save 900 1
#save 300 10
#save 60 10000
dbfilename dump-slave-6380.rdb=
dir /home/hefery/Downloads/Redis/redis/data/log
slaveof 127.0.0.1 6380
appendonly yes
appendfilename "appendonly-slave-6380.aof"
# 连接master-cli,查看master信息
> redis-server redis-master-6379.conf
> redis-cli
> info replication
# Replication
role:master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
# 连接slave-cli,查看slave信息
> redis-server redis-slave-6380.conf
> redis-cli -p 6380 info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:10
master_sync_in_progress:0
slave_repl_offset:71
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
# 连接master-cli录入key,去slave-cli查看
> redis-cli
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> exit
> redis-cli -p 6380
127.0.0.1:6380> get hello
"world"
# slave-cli不能写入key
127.0.0.1:6380> set hello hefery
(error) READONLY You can't write against a read only slave.
全量复制和部分复制
# 查看Redis的run_id
redis-cli -p 6379 info server | grep run
redis-cli -p 6380 info server | grep run
全量复制
全量复制开销;
bgsave时间
RDB文件网络传输时间
从节点清空数据时间从
节点加载RDB的时间可
能的AOF重写时间
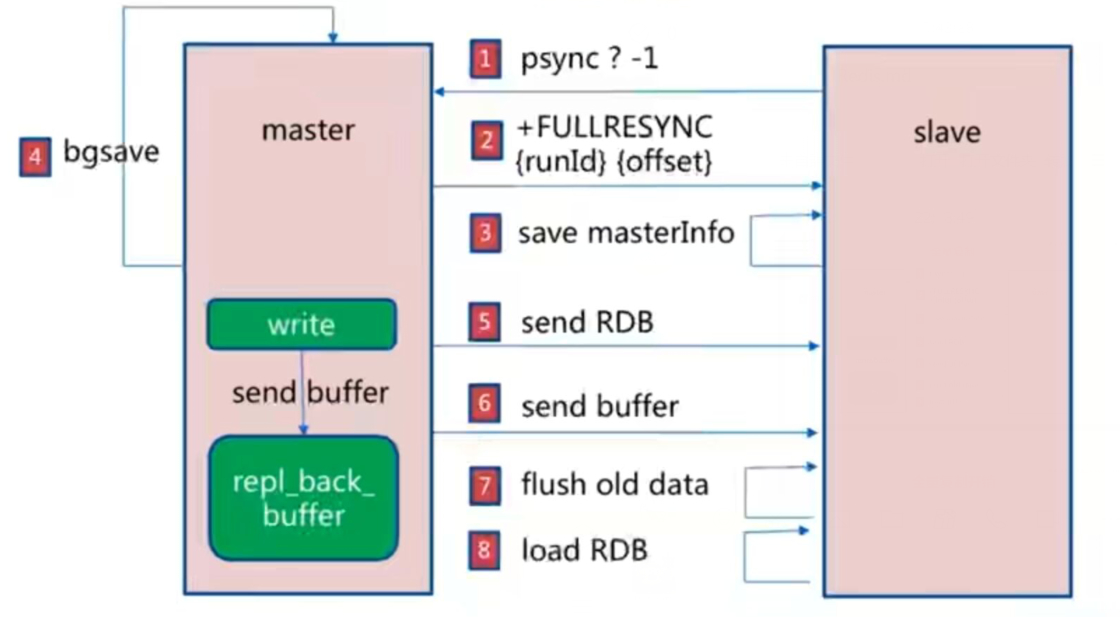
部分复制
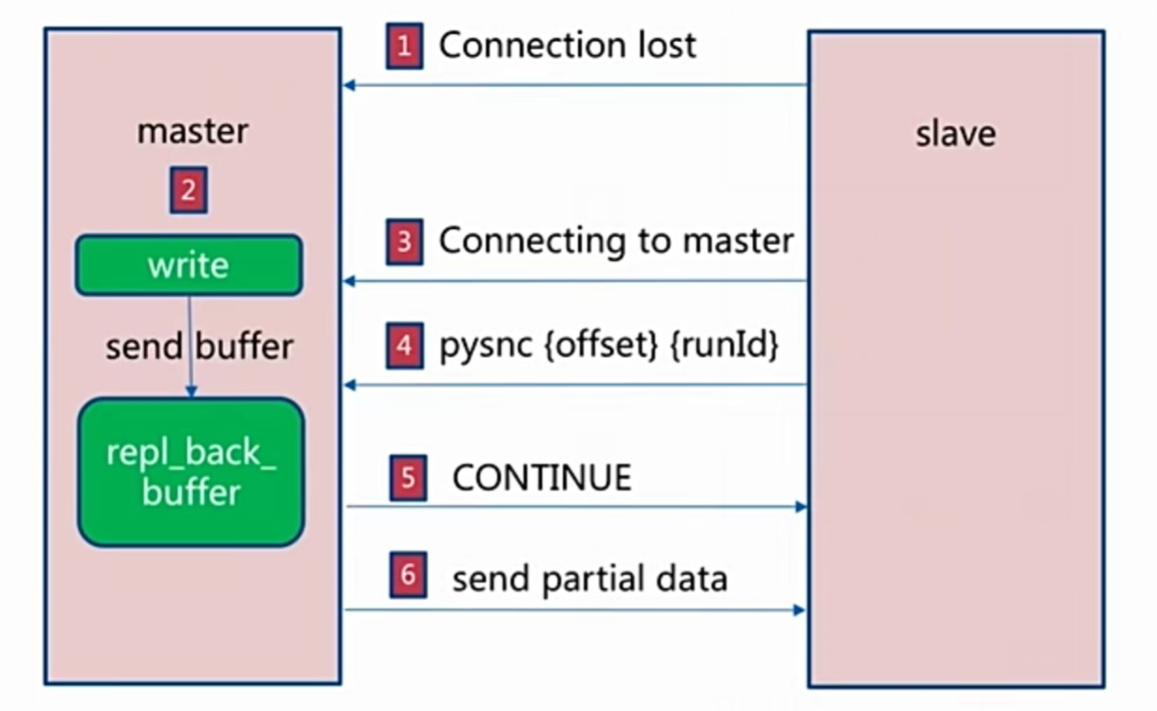
自动故障转移
slave宕机
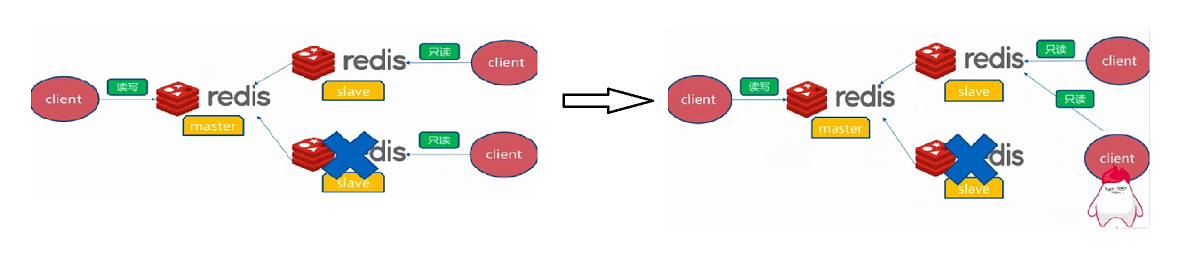
master宕机
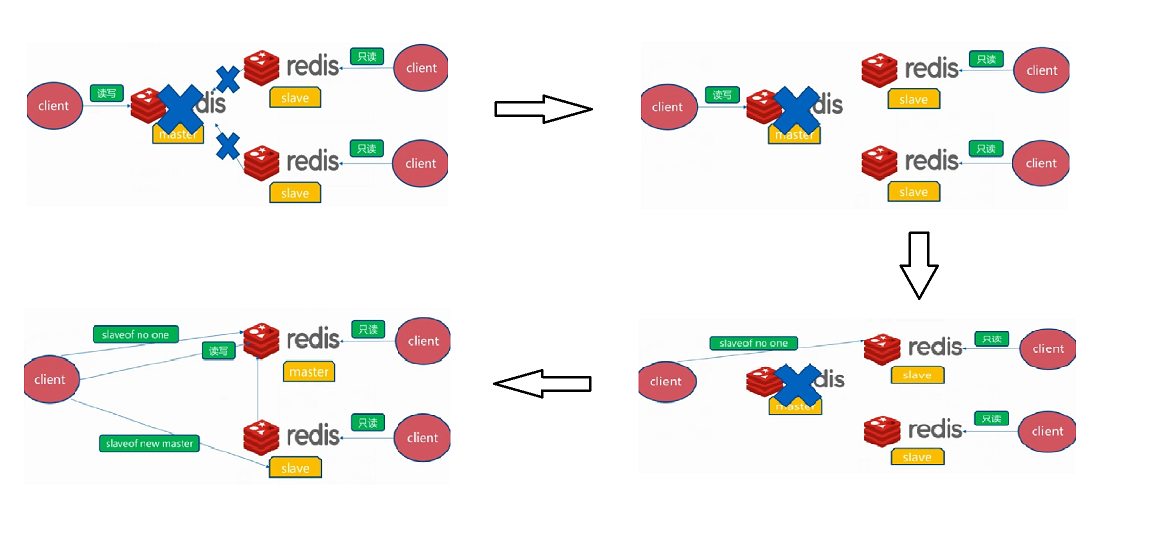
开发运维问题
读写分离
简述:redis-cli写数据在master,读数据在slave
问题:
复制数据延迟
读到过期数据
从节点故障
主从配置不一致
1. maxmemory配置不一致,导致丢数据
2. 数据结构优化参数(hash-max-ziplist-entries),导致内存不一致
规避全量复制
第一次全量复制无法避免
解决:
夜间低峰处理
节点运行ID不匹配
解决:
主节点重启(运行ID变化)
故障转移(集群/哨兵)
复制积压缓冲区不足
原因:网络中断,部分复制无法满足
解决:增大复制缓冲区配置rel_backlog_size,网络增强
规避复制风暴
单主节点复制风暴:
问题:主节点重启,多从节点复制
解决:更换复制拓扑
单机器复制风暴:
机器宕机后,大量全量复制
主节点分散多机器
Redis Sentinel哨兵模式
Sentinel哨兵模式作用就是监控redis集群的运行状况
使用sentinel模式,客户端就不要直接连接Redis,而是连接sentinel的ip和port,由sentinel来提供具体的可提供服务的Redis实现,这样当master节点挂掉以后,sentinel就会感知并将新的master节点提供给使用者
功能:
- 集群监控:负责监控redis master 和slave 进程是否正常工作
- 消息通知:如果某个redis 实例有故障,那么哨兵负责发送消息作为报警通知给管理员
- 故障转移:如果master node挂掉了,会自动转移到slave node上
- 配置中心:如果故障转移发生了,通知client 客户端新的master地址
特点:
- Sentinel模式是建立在主从模式的基础上
- 当 master 挂了以后,sentinel 会在 slave 中选择一个做为 master,并修改它们的配置文件,其他 slave的配置文件也会被修改,比如 slaveof。即使 master 重新启动后恢复,也将不再是 master 而是做为 slave 接收新 master 的同步数据
- 一个 Sentinel 或 Sentinel 集群可以管理多个主从 Redis,多个 Sentinel 也可以监控同一个 Redis
哨兵原理:
- 每个sentinel以每秒钟一次的频率向它所知的master,slave以及其他sentinel实例发送一个 PING 命令
- 如果一个实例距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被sentinel标记为主观下线。如果一个master被标记为主观下线,则正在监视这个master的所有sentinel要以每秒一次的频率确认master的确进入了主观下线状态;当有足够数量的 sentinel(大于等于配置文件指定的值)在指定的时间范围内确认master的确进入了主观下线状态, 则master会被标记为客观下线。在一般情况下, 每个sentinel会以每 10 秒一次的频率向它已知的所有master,slave发送 INFO 命令
- 当master被sentinel标记为客观下线时,sentinel向下线的master的所有slave发送 INFO 命令的频率会从 10 秒一次改为 1 秒一次。若没有足够数量的sentinel同意master已经下线,master的客观下线状态就会被移除。若master重新向sentinel的 PING 命令返回有效回复,master的主观下线状态就会被移除
Sentinel集群搭建
# 配置主节点7000
vim redis-sentinel-7000.conf
port 7000
daemonize yes
pidfile /var/run/redis-sentinel-7000.pid
logfile "redis-sentinel-7000.log"
dir /home/hefery/Downloads/Redis/redis/data/log
# 配置从节点7001+7002
sed "s/7000/7001/g" redis-sentinel-7000.conf > redis-sentinel-7001.conf
sed "s/7000/7002/g" redis-sentinel-7000.conf > redis-sentinel-7002.conf
# 声明主从
echo "slaveof 127.0.0.1 7000" >> redis-sentinel-7001.conf
echo "slaveof 127.0.0.1 7000" >> redis-sentinel-7002.conf
# 启动redis-server
redis-server redis-sentinel-7000.conf
redis-server redis-sentinel-7001.conf
redis-server redis-sentinel-7002.conf
# 查看redis-server启动情况
ps -ef | grep redis-server
root 14251 1 0 22:52 ? 00:00:00 redis-server *:7000
root 16094 1 0 22:53 ? 00:00:00 redis-server *:7001
root 16499 1 0 22:53 ? 00:00:00 redis-server *:7002
root 16686 101512 0 22:53 pts/5 00:00:00 grep --color=auto redis-server
# 查看主节点分片情况
redis-cli -p 7000 info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=7001,state=online,offset=169,lag=0
slave1:ip=127.0.0.1,port=7002,state=online,offset=169,lag=1
master_repl_offset:169
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:168
# 回到redis路径,Copy sentinel.conf到config路径下
cp sentinel.conf ./config/
# 精简sentinel.conf
cat sentinel.conf | grep -v "#" | grep -v "^$" > redis-sentinel-26379.conf
# 配置 redis-sentinel-26379.conf
port 26379
dir /home/hefery/Downloads/Redis/redis/data/log
daemonize yes
logfile "redis-sentinel-26379.log"
sentinel monitor mymaster 127.0.0.1 7000 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
# 启动redis-sentinel
redis-sentinel redis-sentinel-26379.conf
# 查看redis-sentinel启动情况
ps -ef | grep redis-sentinel
# redis-cli连接redis-sentinel
redis-cli -p 26379
# 查看redis-sentinel-26379.conf发生改变
> cat redis-sentinel-26379.conf
port 26379
dir "/home/hefery/Downloads/Redis/redis-3.0.7/data/log"
daemonize yes
logfile "redis-sentinel-26379.log"
sentinel monitor mymaster 127.0.0.1 7000 2
sentinel config-epoch mymaster 0
sentinel leader-epoch mymaster 0
sentinel known-slave mymaster 127.0.0.1 7002
# Generated by CONFIG REWRITE
sentinel known-slave mymaster 127.0.0.1 7001
sentinel current-epoch 0
# 增加redis-sentinel-26380.conf+redis-sentinel-26381.conf
sed "s/26379/26380/g" redis-sentinel-26379.conf > redis-sentinel-26380.conf
sed "s/26379/26381/g" redis-sentinel-26379.conf > redis-sentinel-26381.conf
# 启动26380+26381
redis-sentinel redis-sentinel-26380.conf
redis-sentinel redis-sentinel-26381.conf
ps -ef | grep redis-sentinel
# 登录26379查看 slaves=2,sentinels=3
> info
# Server
redis_version:3.0.7
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:b32e406b52b17276
redis_mode:sentinel
os:Linux 3.10.0-1160.42.2.el7.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
gcc_version:4.8.5
process_id:33120
run_id:c40b4fa3fb2f21de80e2fab27ce29176995c6c16
tcp_port:26379
uptime_in_seconds:39
uptime_in_days:0
hz:15
lru_clock:6662430
config_file:/home/hefery/Downloads/Redis/redis-3.0.7/config/redis-sentinel-26379.conf
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
master0:name=mymaster,status=ok,address=127.0.0.1:7000,slaves=2,sentinels=3
ps -ef | grep redis
root 14251 1 0 22:52 ? 00:00:01 redis-server *:7000
root 16094 1 0 22:53 ? 00:00:01 redis-server *:7001
root 16499 1 0 22:53 ? 00:00:01 redis-server *:7002
root 33120 1 0 23:25 ? 00:00:00 redis-sentinel *:26379 [sentinel]
root 33663 1 0 23:25 ? 00:00:00 redis-sentinel *:26380 [sentinel]
root 33981 1 0 23:25 ? 00:00:00 redis-sentinel *:26381 [sentinel]
Jedis客户端测试
package com.hefery;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisSentinelPool;
import java.security.PrivateKey;
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
import java.util.concurrent.TimeUnit;
/**
* @Author:Hefery
* @Version:1.0.0
* @Date:2021/10/12 23:43
* @Description:
*/
public class RedisSentinelFailoverTest {
private static Logger logger = LoggerFactory.getLogger(RedisSentinelFailoverTest.class);
public static void main(String[] args) {
String masterName = "mymaster";
Set<String> sentinels = new HashSet<String>();
sentinels.add("192.168.1.13:26379");
sentinels.add("192.168.1.13:26380");
sentinels.add("192.168.1.13:26381");
JedisSentinelPool jedisSentinelPool = new JedisSentinelPool(masterName, sentinels);
int counter = 0;
while (true) {
counter++;
Jedis jedis = null;
try {
jedis = jedisSentinelPool.getResource();
int index = new Random().nextInt(100000);
String key = "k-" + index;
String value = "v-" + index;
jedis.set(key, value);
if (counter % 100 == 0) {
logger.info("{} value is {}", key, jedis.get(key));
}
TimeUnit.MICROSECONDS.sleep(10);
} catch (Exception e) {
logger.error(e.getMessage(), e);
} finally {
if (jedis != null) {
jedis.close();
}
}
}
}
}
定时任务
- 每10秒每个sentinel对master和slave执行info
发现slave节点
确认主从关系 - 每2秒每个dentine通过master节点的channel交换信息(pub/sub)
通过_sentinel_:hell频道交互
交互对节点的“看法”和自身信息 - 每1秒每个sentinel对其他sentinel和reds执行ping
Redis Cluster集群模式
通过哈希方式,将数据分片,每个节点均分存储一定哈希槽(哈希值)区间的数据,默认分配了16384个槽位
解决单机Redis容量有限的问题,将Redis的数据根据一定的规则分配到多台机器(cluster = sentinel + 主从)
数据分布
实现:
- 顺序分区:[1-100] -> [1-33]+[34-66]+[67-100]
- 哈希分区:hash(key)%nodes
| 分布形式 | 特点 | 产品 |
|---|---|---|
| 顺序分区 | 数据分散度高;键值分布与业务无关,无法顺序访问;支持批量操作 | Redis Cluster |
| 哈希分区 | 数据分散易倾斜;键值分布与业务相关,可顺序访问;支持批量操作 | HBase,BigTable |
哈希分区:
节点取余分区:hash(key)%nodes
3 node(hash(key)%3):[1-100] -> [3 6 9...]+[1 4...100]+[2 5...98]
4 node(hash(key)%4):[1-100] -> [4 8...100]+[1 5...97]+[2 6...98]+[3 7...99]
扩容:
添加单个:数据迁移80%
倍数扩容:数据迁移50%
一致性哈希分区:token顺时针分配
节点伸缩:只影响临近节点,还是有数据迁移
翻倍伸缩:保证最小迁移数据和负载均衡
虚拟槽分区:
预设虚拟槽:每个槽映射一个数据子集,一般比节点数大
良好的哈希函数:CRC16
服务端管理节点、槽、数据
Redis 集群会有写操作丢失吗?Redis 并不能保证数据的强一致性
Cluster集群搭建
集群架构:
装备节点:
meet:沟通(连通图),节点共享消息
指派槽:给节点指派槽
主从复制:
原生命令
装备节点
port ${port}
daemonize yes
dir /home/hefery/Downloads/Redis/redis/data/log
dbfilename "dump-cluster-${port}.rdb"
logfile "redis-cluster-${port}.log"
cluster-enabled yes
cluster-config-file redis-cluster-nodes-${port}.conf
cluster-node-timeout 15000
cluster-require-full-coverage no
sed 's/7000/7001/g' redis-cluster-7000.conf > redis-cluster-7001.conf
sed 's/7000/7002/g' redis-cluster-7000.conf > redis-cluster-7002.conf
sed 's/7000/7003/g' redis-cluster-7000.conf > redis-cluster-7003.conf
sed 's/7000/7004/g' redis-cluster-7000.conf > redis-cluster-7004.conf
sed 's/7000/7005/g' redis-cluster-7000.conf > redis-cluster-7005.conf
redis-server redis-cluster-7000.conf
redis-server redis-cluster-7001.conf
redis-server redis-cluster-7002.conf
redis-server redis-cluster-7003.conf
redis-server redis-cluster-7004.conf
redis-server redis-cluster-7005.conf
# 查看cluster启动情况
> ps -ef | grep redis
root 2438 1 0 23:17 ? 00:00:00 redis-server *:7000 [cluster]
root 3141 1 0 23:18 ? 00:00:00 redis-server *:7001 [cluster]
root 3395 1 0 23:18 ? 00:00:00 redis-server *:7002 [cluster]
root 114738 1 0 23:11 ? 00:00:00 redis-server *:7003 [cluster]
root 115012 1 0 23:11 ? 00:00:00 redis-server *:7004 [cluster]
root 115527 1 0 23:11 ? 00:00:00 redis-server *:7005 [cluster]
# 查看cluster info信息
> redis-cli -p 7000 cluster info
cluster_state:fail
cluster_slots_assigned:0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:1
cluster_size:0
cluster_current_epoch:0
cluster_my_epoch:0
cluster_stats_messages_sent:0
cluster_stats_messages_received:0
meet
redis-cli -p 7000 cluster meet 127.0.0.1 7001
redis-cli -p 7000 cluster meet 127.0.0.1 7002
redis-cli -p 7000 cluster meet 127.0.0.1 7003
redis-cli -p 7000 cluster meet 127.0.0.1 7004
redis-cli -p 7000 cluster meet 127.0.0.1 7005
> redis-cli -p 7005 cluster nodes
528be9a68ce532a31b838724da23646834c2abf4 127.0.0.1:7003 master - 0 1634140138180 3 connected
523d5b8cfd4e32a65629ff6acd09e933966448ec 127.0.0.1:7004 master - 0 1634140139196 4 connected
6096428be6d89c2c5d43a2125a766fc88a77ba78 127.0.0.1:7001 master - 0 1634140135134 0 connected
10b0195040a76686ebb222ffa363d45bcf4a3de0 127.0.0.1:7000 master - 0 1634140137164 1 connected
326389de2601f42cc48fdd3151c4629b5c3dcdc3 127.0.0.1:7005 myself,master - 0 0 5 connected
2ac8fdc0854b74502bf0b284cf37bd8c82a06d79 127.0.0.1:7002 master - 0 1634140136148 2 connected
# 查看cluster info信息
> redis-cli -p 7000 cluster info
cluster_state:fail
cluster_slots_assigned:0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:0
cluster_current_epoch:5
cluster_my_epoch:1
cluster_stats_messages_sent:2306
cluster_stats_messages_received:2306
指派槽
使用脚本:vim addslots.sh
start=$1
end=$2
port=$3
for slot in `seq ${start} ${end}`
do
echo "slot:${slot}"
redis-cli -p ${port} cluster addslots ${slot}
done
sh addslots.sh 0 5461 7000
sh addslots.sh 5462 10922 7001
sh addslots.sh 10923 16383 7002
# 查看cluster info信息
> redis-cli -p 7005 cluster nodes
528be9a68ce532a31b838724da23646834c2abf4 127.0.0.1:7003 master - 0 1634141761402 3 connected
523d5b8cfd4e32a65629ff6acd09e933966448ec 127.0.0.1:7004 master - 0 1634141758380 4 connected
6096428be6d89c2c5d43a2125a766fc88a77ba78 127.0.0.1:7001 master - 0 1634141763418 0 connected 5462-10922
10b0195040a76686ebb222ffa363d45bcf4a3de0 127.0.0.1:7000 master - 0 1634141760394 1 connected 0-5461
326389de2601f42cc48fdd3151c4629b5c3dcdc3 127.0.0.1:7005 myself,master - 0 0 5 connected
2ac8fdc0854b74502bf0b284cf37bd8c82a06d79 127.0.0.1:7002 master - 0 1634141762410 2 connected 10923-16383
主从复制
从:7003 主:7000
# redis-cli -p 7003 cluster replicate ${node-id-7000}
redis-cli -p 7003 cluster replicate 10b0195040a76686ebb222ffa363d45bcf4a3de0
从:7003 主:7000
# redis-cli -p 7004 cluster replicate ${node-id-7001}
redis-cli -p 7004 cluster replicate 6096428be6d89c2c5d43a2125a766fc88a77ba78
从:7003 主:7000
# redis-cli -p 7005 cluster replicate ${node-id-7002}
redis-cli -p 7005 cluster replicate 2ac8fdc0854b74502bf0b284cf37bd8c82a06d79
# 查看cluster info信息
> redis-cli -p 7000 cluster nodes
528be9a68ce532a31b838724da23646834c2abf4 127.0.0.1:7003 slave 10b0195040a76686ebb222ffa363d45bcf4a3de0 0 1634142192928 3 connected
6096428be6d89c2c5d43a2125a766fc88a77ba78 127.0.0.1:7001 master - 0 1634142194947 0 connected 5462-10922
2ac8fdc0854b74502bf0b284cf37bd8c82a06d79 127.0.0.1:7002 master - 0 1634142195956 2 connected 10923-16383
326389de2601f42cc48fdd3151c4629b5c3dcdc3 127.0.0.1:7005 slave 2ac8fdc0854b74502bf0b284cf37bd8c82a06d79 0 1634142193938 5 connected
523d5b8cfd4e32a65629ff6acd09e933966448ec 127.0.0.1:7004 slave 6096428be6d89c2c5d43a2125a766fc88a77ba78 0 1634142191916 4 connected
10b0195040a76686ebb222ffa363d45bcf4a3de0 127.0.0.1:7000 myself,master - 0 0 1 connected 0-5461
# 查看cluster slot信息
> redis-cli -p 7000 cluster slots
1) 1) (integer) 5462
2) (integer) 10922
3) 1) "127.0.0.1"
2) (integer) 7001
4) 1) "127.0.0.1"
2) (integer) 7004
2) 1) (integer) 10923
2) (integer) 16383
3) 1) "127.0.0.1"
2) (integer) 7002
4) 1) "127.0.0.1"
2) (integer) 7005
3) 1) (integer) 0
2) (integer) 5461
3) 1) "127.0.0.1"
2) (integer) 7000
4) 1) "127.0.0.1"
2) (integer) 7003
Ruby
下载编译安装Ruby
wget https://cache.ruby-lang.org/pub/ruby/2.3/ruby-2.3.1.tar.gz
tar -xvf ruby-2.3.1.tar.gz
cd ruby-2.3.1
./configure #-prefix=/usr/local/ruby
make && make install
cd bin/usr/local/rub
cp bin/ruby/usr/local/bin
cp bin/gem /usr/local/bin
# 查看ruby版本
ruby -v
安装rubygem redis
wget http://rubygems.org/downloads/redis-3.3.0.gem
gem install -l redis-3.3.0.gem
gem list -- check redis gem
安装redis-trib.rb
# cp $(REDIS_ HOME)/src/redis-trib. rb /usr/local/bin
> cd Downloads/Redis/redis/src
> ./redis-trib.rb
Usage: redis-trib <command> <options> <arguments ...>
create host1:port1 ... hostN:portN
--replicas <arg>
check host:port
info host:port
fix host:port
--timeout <arg>
reshard host:port
--from <arg>
--to <arg>
--slots <arg>
--yes
--timeout <arg>
--pipeline <arg>
rebalance host:port
--weight <arg>
--auto-weights
--use-empty-masters
--timeout <arg>
--simulate
--pipeline <arg>
--threshold <arg>
add-node new_host:new_port existing_host:existing_port
--slave
--master-id <arg>
del-node host:port node_id
set-timeout host:port milliseconds
call host:port command arg arg .. arg
import host:port
--from <arg>
--copy
--replace
help (show this help)
For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.
准备节点
port 7000
daemonize yes
dir /home/hefery/Downloads/Redis/redis/data/log
dbfilename "dump-cluster-ruby-7000.rdb"
logfile "redis-cluster-ruby-7000.log"
cluster-enabled yes
cluster-config-file redis-cluster-ruby-nodes-7000.conf
cluster-require-full-coverage no
sed 's/7000/7001/g' redis-cluster-ruby-7000.conf > redis-cluster-ruby-7001.conf
sed 's/7000/7002/g' redis-cluster-ruby-7000.conf > redis-cluster-ruby-7002.conf
sed 's/7000/7003/g' redis-cluster-ruby-7000.conf > redis-cluster-ruby-7003.conf
sed 's/7000/7004/g' redis-cluster-ruby-7000.conf > redis-cluster-ruby-7004.conf
sed 's/7000/7005/g' redis-cluster-ruby-7000.conf > redis-cluster-ruby-7005.conf
redis-server redis-cluster-ruby-7000.conf
redis-server redis-cluster-ruby-7001.conf
redis-server redis-cluster-ruby-7002.conf
redis-server redis-cluster-ruby-7003.conf
redis-server redis-cluster-ruby-7004.conf
redis-server redis-cluster-ruby-7005.conf
> ps -ef | grep redis-server
root 72881 1 0 01:25 ? 00:00:00 redis-server *:7000 [cluster]
root 73203 1 0 01:25 ? 00:00:00 redis-server *:7001 [cluster]
root 73436 1 0 01:25 ? 00:00:00 redis-server *:7002 [cluster]
root 73756 1 0 01:25 ? 00:00:00 redis-server *:7003 [cluster]
root 73992 1 0 01:25 ? 00:00:00 redis-server *:7004 [cluster]
root 74733 1 0 01:26 ? 00:00:00 redis-server *:7005 [cluster]
# redia路径下的redis-trib.rb
cd Downloads/Redis/redis/src
# 使用create创建nodes(选yes)
./redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
Cluster集群扩容
加入集群作用:
- 为它迁移槽和数据实现扩容
- 作为从节点负责故障转移
准备新节点
port ${port}
daemonize yes
dir /home/hefery/Downloads/Redis/redis/data/log
dbfilename "dump-cluster-${port}.rdb"
logfile "redis-cluster-${port}.log"
cluster-enabled yes
cluster-config-file redis-cluster-nodes-${port}.conf
cluster-node-timeout 15000
cluster-require-full-coverage no
sed 's/7000/7006/g' redis-cluster-7000.conf > redis-cluster-7006.conf
sed 's/7000/7007/g' redis-cluster-7000.conf > redis-cluster-7007.conf
redis-server redis-cluster-7006.conf
redis-server redis-cluster-7007.conf
加入集群
redis-cli -p 7000 cluster meet 127.0.0.1 7006
redis-cli -p 7000 cluster meet 127.0.0.1 7007
主从复制
# 7007 replicate 7006
redis-cli -p 7007 cluster replicate 6a0d5b1f102b16ff88a0b621bc2f037798540689
redis-cli -p 7000 cluster nodes
bc125b4301176b75a20b77da37ce5a5111619ccf 127.0.0.1:7004 slave d5f6c8b25537422fde987f4c802d9fb59a07ff94 0 1634223198639 5 connected
c19b6520969c1fc4c0e50475fe73fa1a8ec54fda 127.0.0.1:7002 master - 0 1634223200660 3 connected 10923-16383
4aabd108347571d1123778bfeaddcd7a8e602194 127.0.0.1:7007 slave 6a0d5b1f102b16ff88a0b621bc2f037798540689 0 1634223199650 7 connected
6830085d334270a61508afb3c96e4f6648efb02f 127.0.0.1:7003 slave 49f14b591968ed22462b3a34262f7dcb9e6a8b92 0 1634223201670 4 connected
2163c9c61d776d5f266c1ab687f7cefc7f209feb 127.0.0.1:7005 slave c19b6520969c1fc4c0e50475fe73fa1a8ec54fda 0 1634223195612 6 connected
49f14b591968ed22462b3a34262f7dcb9e6a8b92 127.0.0.1:7000 myself,master - 0 0 1 connected 0-5460
d5f6c8b25537422fde987f4c802d9fb59a07ff94 127.0.0.1:7001 master - 0 1634223197635 2 connected 5461-10922
6a0d5b1f102b16ff88a0b621bc2f037798540689 127.0.0.1:7006 master - 0 1634223199144 0 connected
迁移槽和数据
1.对目标节点发送:cluster setslot{slot} importing {source Nodeld}命令,让目标节点准备导入槽的数据
2.对于源节点发送:cluster setslot {slot} migrating {targetNodeld}命令,让源节点准备迁出槽的数据
3.源节点循环执行:cluster getkeysinslot {slot}{count}命令,毎次获取 count个属于槽的键
4.在源节点上执行:migrate {targetIP} {targetPort} key 0 {timeout}命令把指定key迁移
5.重复执行步骤3~4直到槽下所有的键数据迁移到目标节点
6.向集群内所有主节点发送 cluster setslot{slot) node {targetNodeld}命令,通知槽分配给目标节点
> ./redis-trib.rb reshard 127.0.0.1:7000
How many slots do you want to move (from 1 to 16384)? 4092
What is the receiving node ID? 6a0d5b1f102b16ff88a0b621bc2f037798540689
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:all
Do you want to proceed with the proposed reshard plan (yes/no)? yes
# 查看槽的分配
> redis-cli -p 7000 cluster nodes
bc125b4301176b75a20b77da37ce5a5111619ccf 127.0.0.1:7004 slave d5f6c8b25537422fde987f4c802d9fb59a07ff94 0 1634223721205 5 connected
c19b6520969c1fc4c0e50475fe73fa1a8ec54fda 127.0.0.1:7002 master - 0 1634223719191 3 connected 12286-16383
4aabd108347571d1123778bfeaddcd7a8e602194 127.0.0.1:7007 slave 6a0d5b1f102b16ff88a0b621bc2f037798540689 0 1634223721205 8 connected
6830085d334270a61508afb3c96e4f6648efb02f 127.0.0.1:7003 slave 49f14b591968ed22462b3a34262f7dcb9e6a8b92 0 1634223714154 4 connected
2163c9c61d776d5f266c1ab687f7cefc7f209feb 127.0.0.1:7005 slave c19b6520969c1fc4c0e50475fe73fa1a8ec54fda 0 1634223716677 6 connected
49f14b591968ed22462b3a34262f7dcb9e6a8b92 127.0.0.1:7000 myself,master - 0 0 1 connected 1363-5460
d5f6c8b25537422fde987f4c802d9fb59a07ff94 127.0.0.1:7001 master - 0 1634223717180 2 connected 6826-10922
6a0d5b1f102b16ff88a0b621bc2f037798540689 127.0.0.1:7006 master - 0 1634223720197 8 connected 0-1362 5461-6825 10923-1228
Redis集群模式新增一个服务器时,需要对哈希槽进行rehash,redis提供什么机制保证尽量少的rehash
Redis 集群最大节点个数是多少?16384 个
Redis集群,为什么是16384个槽,槽分配的好处:https://zhuanlan.zhihu.com/p/435994841
Redis 集群没有使用一致性 hash,而是引入了哈希槽的概念,Redis 集群有16384 个哈希槽,每个 key 通过 CRC16 校验后对 16384 取模来决定放置哪个槽,集群的每个节点负责一部分 hash 槽
Cluster集群收缩
# 迁移槽:7006 -> 7000
> ./redis-trib.rb reshard --from 6a0d5b1f102b16ff88a0b621bc2f037798540689 --to 49f14b591968ed22462b3a34262f7dcb9e6a8b92 --slots 1366 127.0.0.1:7006
Do you want to proceed with the proposed reshard plan (yes/no)? yes
# 迁移槽:7006 -> 7001
> ./redis-trib.rb reshard --from 6a0d5b1f102b16ff88a0b621bc2f037798540689 --to d5f6c8b25537422fde987f4c802d9fb59a07ff94 --slots 1366 127.0.0.1:7006
Do you want to proceed with the proposed reshard plan (yes/no)? yes
# 迁移槽:7006 -> 7002
> ./redis-trib.rb reshard --from 6a0d5b1f102b16ff88a0b621bc2f037798540689 --to c19b6520969c1fc4c0e50475fe73fa1a8ec54fda --slots 1366 127.0.0.1:7006
# 查看7006槽以及迁移完毕
> redis-cli -p 7000 cluster nodes
bc125b4301176b75a20b77da37ce5a5111619ccf 127.0.0.1:7004 slave d5f6c8b25537422fde987f4c802d9fb59a07ff94 0 1634224663138 10 connected
c19b6520969c1fc4c0e50475fe73fa1a8ec54fda 127.0.0.1:7002 master - 0 1634224664646 11 connected 10927-16383
4aabd108347571d1123778bfeaddcd7a8e602194 127.0.0.1:7007 slave c19b6520969c1fc4c0e50475fe73fa1a8ec54fda 0 1634224665149 11 connected
6830085d334270a61508afb3c96e4f6648efb02f 127.0.0.1:7003 slave 49f14b591968ed22462b3a34262f7dcb9e6a8b92 0 1634224663640 9 connected
2163c9c61d776d5f266c1ab687f7cefc7f209feb 127.0.0.1:7005 slave c19b6520969c1fc4c0e50475fe73fa1a8ec54fda 0 1634224662132 11 connected
49f14b591968ed22462b3a34262f7dcb9e6a8b92 127.0.0.1:7000 myself,master - 0 0 9 connected 0-5463
d5f6c8b25537422fde987f4c802d9fb59a07ff94 127.0.0.1:7001 master - 0 1634224666154 10 connected 5464-10926
6a0d5b1f102b16ff88a0b621bc2f037798540689 127.0.0.1:7006 master - 0 1634224664143 8 connected
# 下线:7006+7007
> ./redis-trib.rb del-node 127.0.0.1:7000 6a0d5b1f102b16ff88a0b621bc2f037798540689
>>> Removing node 6a0d5b1f102b16ff88a0b621bc2f037798540689 from cluster 127.0.0.1:7000
>>> Sending CLUSTER FORGET messages to the cluster...
>>> SHUTDOWN the node.
> ./redis-trib.rb del-node 127.0.0.1:7000 4aabd108347571d1123778bfeaddcd7a8e602194
>>> Removing node 4aabd108347571d1123778bfeaddcd7a8e602194 from cluster 127.0.0.1:7000
>>> Sending CLUSTER FO
客户端路由
moved重定向:槽已经确定迁移
ask重定向:槽还在迁
smart客户端:JedisCluster
原理:
- 从集群中选—个可运行节点,使用cluster slots初始化槽和节点映射
- 将cluster slots的结果映射到本地,为每个节点创建JedisPool
- 准备执行命令
开发运维问题
集群完整性
cluster-require-full-coverage:
集群中16384个槽全部可用:保证集群完整性
节点故障或者正在故障转移:(error) CLUSTERDOWN The cluster is down
建议:cluster-require-full-coverage no
带宽消耗
避免“大”集群:避免多业务使用一个集群,大业务可以多集群
cluster-node-timeout:带宽和故障转移速度的均衡
cluster-node-timeout=15000,ping/pong带宽为25Mb
cluster-node-timeout=20000,ping/pong带宽低于15Mb
尽量均匀分配到多机器上:保证高可用和带宽
Pub/Sub广播
问题:publish在集群每个节点广播:加重带宽
解决:单独“走”一套 Redis Sentinel
数据倾斜
数据倾斜:内存不均
节点和槽分配不均:
redis-trib.rb info ip:port 查看节点、槽、键值分布
redis-trib.rb rebalance ip:port 进行均衡(谨慎使用)
不同槽对应键值数量差异较大:
CRC16正常情况下比较均匀
可能存在hash_tag
cluster countkeysinslot {slot} 获取槽对应键值个数
包含bigkey:
bigley:例如大字符串、几百万的元素的hash、set等
从节点:redis-cl- bigkeys
优化:优化数据结构
内存相关配置不一致:
hash-max-ziplist-value, set-max-intset-entriesg
优化:定期“检査”配置一致性
请求倾斜:热点
热点key:重要的key或bigkey
优化:
避免 bigley
热键不要用hash_tag
当一致性不高时,可以用本地缓存+MQ
读写分离
只读连接:集群模式的从节点不接受任何读写请求
- 重定向到负责槽的主节点
- readonly命令可以读:连接级别命令
读写分离:更加复杂
同样的问题:复制延迟、读取过期数据、从节点故障
修改客户端:cluster slaves {nodeId}
数据迁移
离线/在线迁移
官方迁移工具:redis- trib. rb import
只能从单机迁移到集群
不支持在线迁移:source需要停写
不支持断点续传
单线程迁移:影响速度
在线迁移:
唯品会 redis-migrate-tool
豌豆荚:redis-port
缓存的使用与设计
缓存好处:
- 加速读写(通过缓存加速读写速度):CPUL1/L2/L3 Cache、 Linux page Cache加速硬盘读写、浏览器缓存、 Ehcache缓存数据库结果
- 降低后端负载(后端服务器通过前端缓存降低负载):业务端使用 Redis降低后端MySQ负载等
缓存成本:
- 数据不一致:缓存层和数据层有时间窗口不一致,和更新策略有关
- 代码维护成本:多了一层缓存逻辑
- 运维成本:例如Redis Cluster
使用场景:
- 降低后端负载:对高消耗的SQL:join结果集/分组统计结果缓存
- 加速请求:响应利用Redis/ Memcache优化IO响应时间
- 大量写合并为批量写:如计数器先 Redis累加再批量写DB
缓存更新策略
- LRU/LFU/FIFO算法剔除:例如 maxmemory-policy
- 超时剔除:例如 expire
- 主动更新:开发控制生命周期
建议:
- 低一致性:最大内存和淘汰策略
- 高一致性∶超时剔除和主动更新结合,最大內存和淘汰策略兜底
| 策略 | 一致性 | 维护成本 |
|---|---|---|
| LRU/LFU/FIFO算法剔除 | 最差 | 低 |
| 超时剔除 | 较差 | 低 |
| 主动更新 | 强 | 高 |
缓存回收策略
过期key处理方案
定期删除+惰性删除:定期删除,Redis 默认每隔 100ms 随机抽取进行检查是否有过期的 key,有过期 key 则删除。如果只采用定期删除策略,会导致很多 key 到时间没有删除。于是,惰性删除派上用场。在获取某个 key 时,Redis 会检查这个 key 如果设置了过期时间那么是否过期了?如果过期就会删除
采用定期删除+惰性删除就没其他问题了么?
不是的,如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性删除也没生效。这样,redis的内存会越来越高。那么就应该采用内存淘汰机制
- 定时删除:在设置键的过期时间的同时,创建一个定时器 timer). 让定时器在键的过期时间来临时,立即执行对键的删除操作
- 定期删除:主动删除,每隔一段时间程序就对数据库进行一次检查,删除里面的过期键。至于要删除多少过期键,以及要检查多少个数据库,则由算法决定
- 惰性删除:被动删除,放任键过期不管,但是每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就删除该键;如果没有过期,就返回该键
设置过期时间:expire 或 setex
为什么不用定时删除策略?
定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源。在大并发请求下,CPU要将时间应用在处理请求,而不是删除key,因此没有采用这一策略
API:
- dbsize:返回的 Key 数量,包含了过期 Key
- randomkey:返回的 Key,不包含过期 Key
- scan:返回的 Key,包含过期 Key
- info:返回的 Keyspace:db6:keys=1034937352,expires=994731489,avg_ttl=507838502
- expires:设置了过期时间的 Key 数量
- avg_ttl:设置了过期时间的 Key 的平均过期时间(单位:毫秒)
Redis key 的过期时间和永久有效分别怎么设置EXPIRE 和 PERSIST 命令
设置缓存限定值
maxmemory:为了将 redis 的使用内存限定在一个固定的大小,当使用内存超出限定值后,根据maxmemory-policy 配置的策略进行内存回收
设置maxmemory:
- congfig set 命令行:
# 获取 maxmemory config get maxmemory # 设置 maxmemory config set maxmemory 1024MB - redis.conf 配置文件:
maxmemory 1024MB
不配置 maxmemory 的值时,将默认为0
淘汰策略
- noeviction 策略 : 当 Redis 缓存达到了 maxmemory 配置的值后,再有写入请求到来时,redis 将不再提供写入服务,直接响应错误
- volatile-ttl 策略 : 在筛选时,会针对设置了过期时间的键值对,根据过期时间的先后进行删除,越早过期的越先被删除
- volatile-random 策略 : 在设置了过期时间的键值对中,进行随机删除
- volatile-lru 策略 :使用 LRU 算法筛选设置了过期时间的键值对
- volatile-lfu 策略 : 使用 LFU 算法选择设置了过期时间的键值对
- allkeys-random 策略,从所有键值对中随机选择并删除数据
- allkeys-lru 策略,使用 LRU 算法在所有数据中进行筛选
- allkeys-lfu 策略,使用 LFU 算法在所有数据中进行筛选
Redis的过期Keys有哪些删除策略
缓存粒度控制
缓存粒度控制角度:
- 通用性:全量属性更好
- 占用空间:部分属性更好
- 代码维护:表面上全量属性更好
缓存问题隐患
缓存穿透
缓存穿透:某一时刻访问 Redis 的大量 key 不命中缓存(查询不存在的数据),就绕过缓存直接查询 DB 也查不到(缓存不存在,数据库不存在)
request -> cache(miss) -> storage(miss) -> request(return null)
解决:
- 给没有命中的 key 设定“没有意义的空值”
- 设置参数合法性校验
- 布隆过滤器拦截,在访问Redis前先判断数据是否存在。所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法,如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。通过这个直接设置的默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库
缓存击穿
缓存击穿:某一个热点key突然失效,导致大量请求直接访问MySQL(缓存不存在,数据库存在)
解决方案:热点key不设过期时间
缓存雪崩
缓存雪崩:同一时间 Redis 大批热点数据同时过期(缓存设置相同过期时间),导致大量请求转发直接访问DB,DB 的瞬时压力过大,造成级联故障(缓存不存在,数据库存在)
优化:Redis Cluster、Redis Sentinel
- 给 key 设定不同的(随机的)过期时间
- 保证缓存高可用性:个别节点、个别机器、甚至是机房,例如Redis Cluster、Redis Sentinel、VIP
- 依赖隔离组件为后端限流:依赖隔离组件——线程池/信号量隔离组件
- 提前演练:例如压力测试
缓存更新
缓存更新:系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据
解决:
- 数据量不大,可以在项目启动的时候自动进行加载
- 定时刷新缓存
缓存预热
缓存预热:除了缓存服务器自带的缓存失效策略之外(Redis默认的有6种策略可供选择),还可以根据具体的业务需求进行自定义的缓存淘汰
解决:
- 定时去清理过期的缓存,维护大量缓存的key是比较麻烦的
- 当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存,每次用户请求过来都要判断缓存失效,逻辑相对比较复杂
缓存降级
缓存降级:当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级
降级最终目的:保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入购物车、结算)
无底洞问题
问题描述:2010年, Facebook有了3000个 Memcache节点
发现问题:“加”机器性能没能提升,反而下降
问题关键:
更多的机器不代表更高的性能
批量接口需求(mget, mset等)
数据增长与水平扩展需求
优化:
IO优化:
命令本身优化:例如慢查询keys、 hgetall bigkey
减少网络通信次数
降低接入成本∶例如客户端长连接/连接池、NIO等
批量优化的方法:
串行mget
串行IO
并行IO
hash_tag
| 方案 | 优点 | 缺点 | 网络IO |
|---|---|---|---|
| 串行mget | 编程简单,少量keys满足需求 | 大量keys请求延迟严重 | O(keys) |
| 串行IO | 编程简单,少量节点满足需求 | 大量node延迟严重 | O(node) |
| 并行IO | 利用并行特性,延迟取决于最慢的节点 | 编程复杂,超时定位问题难 | O(max_slow(node)) |
| hash_tag | 性能最高 | 读写增加tag维护成本,tag分布易出现数据倾斜 | O(1) |
热点key重建
可题描述:热点key+较长的重建时间
目标:
减少重缓存的次数
数据尽可能一致
减少潜在危险
解决:
互斥锁:
永远不过期:
缓存层面:没有设置过期时间没有用 expire
功能层面:为每个value添加逻辑过期时间,但发现超过逻辑过期时间后,会使用单独的线程去构建缓存
热点数据和冷数据
热点数据,缓存才有价值
对于冷数据而言,大部分数据可能还没有再次访问到就已经被挤出内存,不仅占用内存,而且价值不大。频繁修改的数据,看情况考虑使用缓存
寿星列表、导航信息都存在一个特点,就是信息修改频率不高,读取通常非常高的场景
对于热点数据,比如我们的某IM产品,生日祝福模块,当天的寿星列表,缓存以后可能读取数十万次。再举个例子,某导航产品,我们将导航信息,缓存以后可能读取数百万次
数据更新前至少读取两次,缓存才有意义,如果缓存还没有起作用就失效了,那就没有太大价值了
存在修改频率很高,但是又不得不考虑缓存的场景,比如,这个读取接口对数据库的压力很大,但是又是热点数据,这个时候就需要考虑通过缓存手段,减少数据库的压力,比如我们的某助手产品的,点赞数,收藏数,分享数等是非常典型的热点数据,但是又不断变化,此时就需要将数据同步保存到Redis缓存,减少数据库压力
| 方案 | 优点 | 缺点 |
|---|---|---|
| 互斥锁 | 思路简单,保证一致性 | 代码复杂度增加,存在死锁的风险 |
| 永远不过期 | 基本杜绝热点key重建问题 | 不保证一致性,逻辑过期时间增加维护成本和内存成本 |
热点数据倾斜
缓存与数据库双写一致性问题
- 先更新 MySQL,再更新 Redis。如果 MySQL 更新完成后,再更新 Redis 缓存失败,数据仍然不一致
方案:将热点数据缓存设置永不过期,但在 value 当中写入逻辑上的过期时间,启动一个后台线程,扫描这些 key,对于逻辑上过期的缓存进行删除(保证一定时间内数据的最终一致性) - 先删除 Redis 缓存数据,再更新 MySQL,再次查询的时候在将数据添加到缓存,这种方案能解决方案1的问题,但是在高并发下性能较低,而且仍然会出现数据不一致的问题,比如线程1删除了 Redis 缓存数据,正在更新 MySQL,线程2再查询缓存为空,那么就会把 MySQL 中老数据又缓存到Redis
方案:延时双删:先删除 Redis 缓存,再更新 MySQL,延迟几百毫秒再删除 Redis 缓存,这样就算在更新MySQL时,有其他线程读了MySQL,把老数据读到了Redis,那么也会被删除掉,从而把数据保持一致
Redis布隆过滤器
位图:int[10],每个int类型的整数是4*8=32个bit,则int[10]一共有320bit,每个bit非o即1,初始化时都是0
添加数据时,将数据进行hash得到hash值,对应到bit位,将该bit改为1,hash函数可以定义多个,则一个数据添加会将多个(hash函数个数)bit改为1,多个hash函数的目的是减少hash碰撞的概率
查询数据:hash函数计算得到hash值,对应到bit中,如果有一个为0,则说明数据不在bit中,如果都为1,则该数据可能在bit中
优点:
- 占用内存小
- 增加和查询元素的时间复杂度为:O(K),(K为哈希函数的个数,一般比较小),与数据量大小无关
- 哈希函数相互之间没有关系,方便硬件并行运算
- 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
- 数据量很大时,布隆过滤器可以表示全集
- 使用同一组散列函数的布隆过滤器可以进行交、并、差运算
缺点:
- 误判率,即存在假阳性(False Position),不能准确判断元素是否在集合中
- 不能获取元素本身
- 一般情况下不能从布隆过滤器中删除元素
布隆过滤器原理
实现原理:一个很长的二进制向量和若干个哈希函数
布隆过滤器构建:
参数:m个二进制向量,n个预备数据,k个hash函数
布隆过滤器是不能删除元素的,这也是布隆过滤器的缺点
布隆过滤器原理:
布隆过滤器误差率
肯定存在误差:恰好都命中了
直观因素:m/n的比率,hash函数的个数
m/n与误差率成反比,k与误差率成反比
Redis开发规范
Key名设计
可读性和管理性:以业务名(或数据库名)为前缀(防止key冲突),用冒号分割可
如:业务名表名id,如:ugc:video:1
简洁性:保证语义的前提下,控制key的长度,当key较多时,内存占用也不容忽视(reds3:39字节embstr)
如:user:{uid}:friends:messages:{mid} -> u:{uid}:fr:m:{mid}
不要包含特殊字符:反例:包含空格、换行、单双引号以及其他转义字符
Value设计
bigley:
强制:
1.string类型控制在10KB以内
2.hash、list、set、zset元素个数不要超过5000
反例:一个包含几百万个元素的list、hash等,一个巨大的json字符串
危害:
1.网络阻塞
2.Redis阻塞:慢查询,hgetall、lrange、zgrange
3.集群节点数据不均衡
4.频繁序列化:应用服务器CPU消耗
反序列消耗:
Redis客户端本身不负责序列化
应用频繁序列化和反序列化 bigley:本地缓存或 Redis缓存
发现:
1.应用异常
2.redis-ci --bigkeys
3.scan + debug object
4.主动报警:网络流量监控、客户端监控
5.内核热点key问题优化
删除:
阻塞:注意隐性删除(过期、 rename等)
Reds4.0:lazy delete( unlink命令)
优化:
优化数据结构:例如二级拆分
物理隔离或者万兆网卡:不是治标方案
命令优化:例如hgetall --> hmget、scan
报警和定期优化
Redisson分布式锁
实现原理:
- 首先利用setnx来保证:如果key不存在才能获取到锁,如果key存在,则获取不到锁
- 然后还要利用lua脚本来保证多个redis操作的原子性
- 同时还要考虑到锁过期,所以需要额外的一个看门狗定时任务来监听锁是否需要续约
- 同时还要考虑到redis节点挂掉后的情况,所以需要采用红锁的方式来同时向N/2+1个节点申请锁,都申请到了才证明获取锁成功,这样就算其中某个redis节点挂掉了,锁也不能被其他客户端获取到