
Kafka简介
Kafka简介
Kafka:
- 消息引擎系统(Messaging System),基于 Zookeeper 分布式消息队列(发布/订阅模式)
- 分布式事件流平台(Distributed Streaming Platform),用于高性能数据管道、流分析、数据集成和关键任务应用
消息引擎系统是一组规范。企业利用这组规范在不同系统之间传递语义准确的消息,实现松耦合的异步式数据传递。
消息引擎是用于在不同系统之间传输消息,那么如何设计待传输消息的格式—Kafka使用纯二进制的字节序列。当然消息还是结构化的,只是在使用之前都要将其转换成二进制的字节序列
特点:实时、高吞吐率、高性能、高可靠
Kafka作为消息队列的作用:
- 削峰填谷:缓冲上下游瞬时突发流量,使其更平滑。特别是对于那种发送能力很强的上游系统,如果没有消息引擎的保护,“脆弱”的下游系统可能会直接被压垮导致全链路服务“雪崩”。但是,一旦有了消息引擎,它能够有效地对抗上游的流量冲击,真正做到将上游的“峰”填满到“谷”中,避免了流量的震荡。消息引擎系统的另一大好处在于发送方和接收方的松耦合,这也在一定程度上简化了应用的开发,减少了系统间不必要的交互。引入像 Kafka 这样的消息引擎系统来对抗这种上下游系统 TPS 的错配以及瞬时峰值流量。
- 解耦:允许独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束
- 异步通信:把一个消息放入队列,但并不立即处理它,然后在需要的时候再去处理它们
Kafka工作模型
- 点对点模型:
- 系统 A 发送的消息只能被系统 B 接收,其他任何系统都不能读取 A 发送的消息
- 发布/订阅模型:
- 可能存在多个发布者向相同的主题 topic 发送消息,而订阅者也可能存在多个,它们都能接收到相同主题的消息
- 消费者消费数据之后,不删除数据
Kafka基本概念
消息:
- Record:消息,Kafka 处理的主要对象
- Topic:主题,由 Partition 组成,承载 Record 的逻辑容器,在实际使用中多用来区分具体的业务。
- 发布订阅的对象是 Topic,可以为每个业务创建专属的主题
- 每个主题可以配置 M 个分区Partition,而每个分区 Partition 又可以配置 N 个副本Replica
- Partition:分区,实际消息存储单位。将每个 Topic 划分成多个分区。每个分区都是一个有序的,不可变的记录序列,不断附加到结构化的提交日志中
- 分区中的记录每个都分配了一个称为偏移的顺序ID号,它唯一地标识分区中的每个记录
- 分区作用:提供负载均衡的能力,或说对数据进行分区主要原因,就是为了实现系统的高伸缩性
- 分区策略:轮询、随机、按消息键key保存……
- Offset:消息位移,分区中每条 Record 位置信息,分区位移总是从 0 开始
客户端:
- Producer:消息生产者,通常持续不断地向一个或多个 Topic 发送消息的客户端
- Consumer:消息消费者,订阅一个或多个 Topic 消息并进行消费的客户端
生产者向分区写入消息,每条消息在分区中的位置信息由一个叫偏移量(Offset)的数据来表征。分区位移总是从 0 开始,假设一个生产者向一个空分区写入了 10 条消息,那么这 10 条消息的位移依次是 0、1、2、…、9
服务端:
- Broker :一个 Kafka 集群由多个 Broker 组成,Broker 负责接收和处理客户端发送过来的请求,以及对消息进行持久化。
- Replica:副本,为保证集群中的某个节点发生故障时,该节点上的 Partition 数据不丢失,且 Kkafka 仍然能够继续工作,Kafka 提供了副本机制,一个 Topic 的每个分区都有若干个副本
Broker 如何持久化数据:Kafka 使用消息日志(Log)来保存数据,一个日志就是磁盘上一个只能追加写(Append-only)消息的物理文件。因为只能追加写入,故避免了缓慢的随机 I/O 操作,改为性能较好的顺序I/O 写操作,这也是实现 Kafka 高吞吐量特性的一个重要手段。不过如果你不停地向一个日志写入消息,最终也会耗尽所有的磁盘空间,因此 Kafka 必然要定期地删除消息以回收磁盘。怎么删除呢?简单来说就是通过日志段(Log Segment)机制。在 Kafka 底层,一个日志又近一步细分成多个日志段,消息被追加写到当前最新的日志段中,当写满了一个日志段后,Kafka 会自动切分出一个新的日志段,并将老的日志段封存起来。Kafka 在后台还有定时任务会定期地检查老的日志段是否能够被删除,从而实现回收磁盘空间的目的
Kafka操作
Kafka安装部署
Kafka版本:kafka_2.12-3.1.0.tgz(编译 Kafka 源代码的 Scala 编译器版本 + Kafka 版本号)
选择合适的 Kafka 版本:每个 Kafka 版本都有恰当使用场景和独特优缺点,切记不要一味追求最新版本
-
Zookeeper
- 解压:
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/install/ - 配置:
vim config/zookeeper.properties - 启动:
nohup bin/zookeeper-server-start.sh config/zookeeper.properties & - 验证:
ps -ef | grep zookeeper
- 解压:
-
Kafuka
- 解压:
tar -zxvf kafka_2.11-2.4.0.tgz -C /opt/install/ - 配置:
vim config/server.properties - 启动:
nohup bin/kafka-server-start.sh config/server.properties & - 验证:
ps -ef | grep kafka - 停止:
bin/kafka-server-stop.sh
- 解压:
启动时:先启 Zookeeper,再启 Kafka
关闭时:先关 Kafka,再关 Zookeeper
Kafka配置文件
# 每个 broker 在集群中的唯一标识,要求是正数
broker.id=0
# Kafka数据存放地址,多个地址的话用逗号分割 /tmp/kafka-logs-1,/tmp/kafka-logs-2
log.dirs=/tmp/kafka-logs
# Zookeeper集群的地址,多个地址用逗号分割 hostname1:port1, hostname2:port2, hostname3:port3
zookeeper.connect=localhost:2181
# kafka真正bind的地址:定义 Kafka Broker 的 Listener 配置项
listeners
# 将 Broker 的 Listener 信息发布到 Zookeeper 中,暴露给外部 listeners,如果没有设置,会用 listeners
advertised.listeners
Kafka核心API
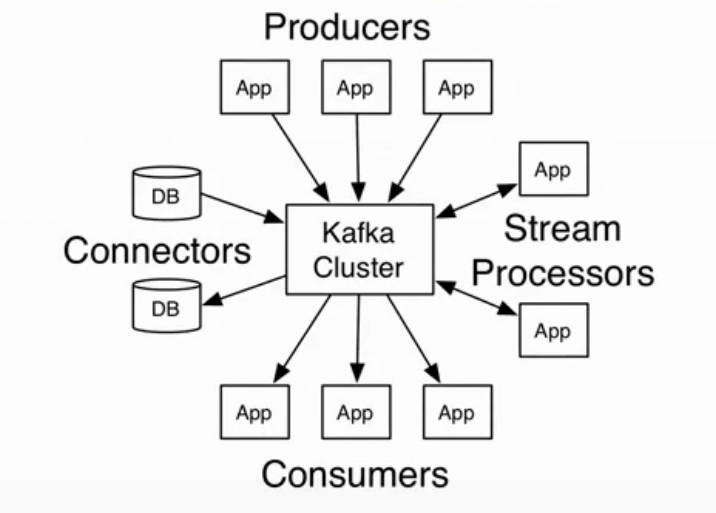
Kafka客户端 AP
- AdminClient:Kafka 管理和检测 Topic、broker 以及其它 Kafka 对象
- Producer:发布消息到1个或多个topic
- Consumer:订阅一个或多个topic,并处理产生的消息
- Streams:高效地将输入流转换到输出流
- Connector:从一些源系统或应用程序中拉取数据到kafka
AdminClient API
| API | 作用 |
|---|---|
| AdminClient | AdminClient客户端对象 |
| NewTopic | 创建Topic |
| CreateTopicsResult | 创建Topic的返回结果 |
| ListTopicsResult | 查询Topic列表 |
| ListTopicsOptions | 查询Topic列表及选项 |
| DescribeTopicsResult | 查询Topics详情 |
| DescribeConfigsResult | 查询Topics配置项 |
public class AdminSample {
public final static String TOPIC_NAME = "lalala-topic";
public static void main(String[] args) throws Exception {
// 设置AdminClient
AdminClient adminClient = AdminSample.adminClient();
//System.out.println("AdminClient:" + adminClient);
// 创建Topic实例
//createTopic();
// 获取Topic列表
//topicList();
// 删除Topic实例
//delTopics();
// 描述Topic
//describeTopics();
// 查询Config
//describeConfig();
// 修改Config
//alterConfig();
// 增加partition数量
incrPartitions(2);
}
/*
增加partition数量
*/
public static void incrPartitions(int partitions) throws Exception{
AdminClient adminClient = adminClient();
Map<String, NewPartitions> partitionsMap = new HashMap<>();
NewPartitions newPartitions = NewPartitions.increaseTo(partitions);
partitionsMap.put(TOPIC_NAME, newPartitions);
CreatePartitionsResult createPartitionsResult = adminClient.createPartitions(partitionsMap);
createPartitionsResult.all().get();
}
/*
修改Config信息
*/
public static void alterConfig() throws Exception{
AdminClient adminClient = adminClient();
// Map<ConfigResource,Config> configMaps = new HashMap<>();
// 组织两个参数
// ConfigResource configResource = new ConfigResource(ConfigResource.Type.TOPIC, TOPIC_NAME);
// Config config = new Config(Arrays.asList(new ConfigEntry("preallocate","true")));
// configMaps.put(configResource,config);
// AlterConfigsResult alterConfigsResult = adminClient.alterConfigs(configMaps);
/*
从 2.3以上的版本新修改的API
*/
Map<ConfigResource,Collection<AlterConfigOp>> configMaps = new HashMap<>();
// 组织两个参数
ConfigResource configResource = new ConfigResource(ConfigResource.Type.TOPIC, TOPIC_NAME);
AlterConfigOp alterConfigOp =
new AlterConfigOp(new ConfigEntry("preallocate","false"),AlterConfigOp.OpType.SET);
configMaps.put(configResource,Arrays.asList(alterConfigOp));
AlterConfigsResult alterConfigsResult = adminClient.incrementalAlterConfigs(configMaps);
alterConfigsResult.all().get();
}
/*
查看配置信息
ConfigResource(type=TOPIC, name='jiangzh-topic') ,
Config(
entries=[
ConfigEntry(
name=compression.type,
value=producer,
source=DEFAULT_CONFIG,
isSensitive=false,
isReadOnly=false,
synonyms=[]),
ConfigEntry(
name=leader.replication.throttled.replicas,
value=,
source=DEFAULT_CONFIG,
isSensitive=false,
isReadOnly=false,
synonyms=[]), ConfigEntry(name=message.downconversion.enable, value=true, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=min.insync.replicas, value=1, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=segment.jitter.ms, value=0, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=cleanup.policy, value=delete, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=flush.ms, value=9223372036854775807, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=follower.replication.throttled.replicas, value=, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=segment.bytes, value=1073741824, source=STATIC_BROKER_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=retention.ms, value=604800000, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=flush.messages, value=9223372036854775807, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=message.format.version, value=2.4-IV1, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=file.delete.delay.ms, value=60000, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=max.compaction.lag.ms, value=9223372036854775807, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=max.message.bytes, value=1000012, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=min.compaction.lag.ms, value=0, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=message.timestamp.type, value=CreateTime, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]),
ConfigEntry(name=preallocate, value=false, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=min.cleanable.dirty.ratio, value=0.5, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=index.interval.bytes, value=4096, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=unclean.leader.election.enable, value=false, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=retention.bytes, value=-1, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=delete.retention.ms, value=86400000, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=segment.ms, value=604800000, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=message.timestamp.difference.max.ms, value=9223372036854775807, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=segment.index.bytes, value=10485760, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[])])
*/
public static void describeConfig() throws Exception{
AdminClient adminClient = adminClient();
// TODO 这里做一个预留,集群时会讲到
// ConfigResource configResource = new ConfigResource(ConfigResource.Type.BROKER, TOPIC_NAME);
ConfigResource configResource = new ConfigResource(ConfigResource.Type.TOPIC, TOPIC_NAME);
DescribeConfigsResult describeConfigsResult = adminClient.describeConfigs(Arrays.asList(configResource));
Map<ConfigResource, Config> configResourceConfigMap = describeConfigsResult.all().get();
configResourceConfigMap.entrySet().stream().forEach((entry)->{
System.out.println("configResource : "+entry.getKey()+" , Config : "+entry.getValue());
});
}
/*
描述Topic
name :jiangzh-topic ,
desc: (name=jiangzh-topic,
internal=false,
partitions=
(partition=0,
leader=192.168.220.128:9092
(id: 0 rack: null),
replicas=192.168.220.128:9092
(id: 0 rack: null),
isr=192.168.220.128:9092
(id: 0 rack: null)),
authorizedOperations=[])
*/
public static void describeTopics() throws Exception {
AdminClient adminClient = adminClient();
DescribeTopicsResult describeTopicsResult = adminClient.describeTopics(Arrays.asList(TOPIC_NAME));
Map<String, TopicDescription> stringTopicDescriptionMap = describeTopicsResult.all().get();
Set<Map.Entry<String, TopicDescription>> entries = stringTopicDescriptionMap.entrySet();
entries.stream().forEach((entry)->{
System.out.println("name :"+entry.getKey()+" , desc: "+ entry.getValue());
});
}
/**
* 删除Topic
* @throws Exception
*/
public static void delTopics() throws Exception {
AdminClient adminClient = adminClient();
DeleteTopicsResult deleteTopicsResult = adminClient.deleteTopics(Arrays.asList(TOPIC_NAME));
deleteTopicsResult.all().get();
}
/**
* 获取Topic列表
* @throws ExecutionException
* @throws InterruptedException
*/
public static void topicList() throws ExecutionException, InterruptedException {
AdminClient adminClient = adminClient();
// 是否查看internal选项
ListTopicsOptions options = new ListTopicsOptions();
options.listInternal(true);
//ListTopicsResult listTopicsResult = adminClient.listTopics();
ListTopicsResult listTopicsResult = adminClient.listTopics(options);
Set<String> names = listTopicsResult.names().get();
Collection<TopicListing> topicListings = listTopicsResult.listings().get();
KafkaFuture<Map<String, TopicListing>> mapKafkaFuture = listTopicsResult.namesToListings();
// 打印names
names.stream().forEach(System.out::println);
// 打印topicListings
topicListings.stream().forEach((topicList)->{
System.out.println(topicList);
});
}
/**
* 创建Topic实例
*/
public static void createTopic() {
AdminClient adminClient = adminClient();
// bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic hefery-topic
Short rs = 1; // 副本因子
NewTopic newTopic = new NewTopic(TOPIC_NAME, 1, rs);
CreateTopicsResult topics = adminClient.createTopics(Arrays.asList(newTopic));
System.out.println("CreateTopicsResult:" + topics);
}
/**
* 设置AdminClient
* @return
*/
public static AdminClient adminClient() {
Properties properties = new Properties();
properties.setProperty(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.153.128:9092");
AdminClient adminClient = AdminClient.create(properties);
return adminClient;
}
}
Producer APl
Producer发送模式
- 同步发送
public class ProducerSample { private final static String TOPIC_NAME="hefery-topic"; public static void main(String[] args) { // 同步:Producer异步阻塞发送 producerSyncSend(); } /* 同步:Producer异步阻塞发送 */ public static void producerSyncSend() throws ExecutionException, InterruptedException { Properties properties = new Properties(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.153.128:9092"); properties.put(ProducerConfig.ACKS_CONFIG,"all"); properties.put(ProducerConfig.RETRIES_CONFIG,"0"); properties.put(ProducerConfig.BATCH_SIZE_CONFIG,"16384"); properties.put(ProducerConfig.LINGER_MS_CONFIG,"1"); properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,"33554432"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); // Producer的主对象 Producer<String,String> producer = new KafkaProducer<>(properties); // 消息对象 - ProducerRecoder for(int i=0;i<10;i++){ String key = "key-"+i; ProducerRecord<String,String> record = new ProducerRecord<>(TOPIC_NAME,key,"value-"+i); Future<RecordMetadata> send = producer.send(record); RecordMetadata recordMetadata = send.get(); System.out.println(key + "partition : "+recordMetadata.partition()+" , offset : "+recordMetadata.offset()); } // 所有的通道打开都需要关闭 producer.close(); } } - 异步发送
public class ProducerSample { private final static String TOPIC_NAME="hefery-topic"; public static void main(String[] args) { // Producer异步发送演示 producerSend(); } /** * Producer异步发送演示 */ public static void producerSend() { Properties properties = new Properties(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.153.128:9092"); properties.put(ProducerConfig.ACKS_CONFIG,"all"); properties.put(ProducerConfig.RETRIES_CONFIG,"0"); properties.put(ProducerConfig.BATCH_SIZE_CONFIG,"16384"); properties.put(ProducerConfig.LINGER_MS_CONFIG,"1"); properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,"33554432"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); // Producer的主对象 Producer<String,String> producer = new KafkaProducer<>(properties); // 消息对象 - ProducerRecoder for(int i=0;i<10;i++){ ProducerRecord<String,String> record = new ProducerRecord<>(TOPIC_NAME,"key-"+i,"value-"+i); producer.send(record); } // 所有的通道打开都需要关闭 producer.close(); } } - 异步回调发送
public class ProducerSample { private final static String TOPIC_NAME="hefery-topic"; public static void main(String[] args) { /// Producer异步发送带回调函数 producerSendWithCallback(); // Producer异步发送带回调函数和Partition负载均衡 producerSendWithCallbackAndPartition(); } /* Producer异步发送带回调函数和Partition负载均衡 */ public static void producerSendWithCallbackAndPartition(){ Properties properties = new Properties(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.153.128:9092"); properties.put(ProducerConfig.ACKS_CONFIG,"all"); properties.put(ProducerConfig.RETRIES_CONFIG,"0"); properties.put(ProducerConfig.BATCH_SIZE_CONFIG,"16384"); properties.put(ProducerConfig.LINGER_MS_CONFIG,"1"); properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,"33554432"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.imooc.jiangzh.kafka.producer.SamplePartition"); // Producer的主对象 Producer<String,String> producer = new KafkaProducer<>(properties); // 消息对象 - ProducerRecoder for(int i=0;i<10;i++){ ProducerRecord<String,String> record = new ProducerRecord<>(TOPIC_NAME,"key-"+i,"value-"+i); producer.send(record, new Callback() { @Override public void onCompletion(RecordMetadata recordMetadata, Exception e) { System.out.println( "partition : "+recordMetadata.partition()+" , offset : "+recordMetadata.offset()); } }); } // 所有的通道打开都需要关闭 producer.close(); } /* Producer异步发送带回调函数 */ public static void producerSendWithCallback(){ Properties properties = new Properties(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.153.128:9092"); properties.put(ProducerConfig.ACKS_CONFIG,"all"); properties.put(ProducerConfig.RETRIES_CONFIG,"0"); properties.put(ProducerConfig.BATCH_SIZE_CONFIG,"16384"); properties.put(ProducerConfig.LINGER_MS_CONFIG,"1"); properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,"33554432"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); // Producer的主对象 Producer<String,String> producer = new KafkaProducer<>(properties); // 消息对象 - ProducerRecoder for(int i=0;i<10;i++){ ProducerRecord<String,String> record = new ProducerRecord<>(TOPIC_NAME,"key-"+i,"value-"+i); producer.send(record, new Callback() { @Override public void onCompletion(RecordMetadata recordMetadata, Exception e) { System.out.println( "partition : "+recordMetadata.partition()+" , offset : "+recordMetadata.offset()); } }); } // 所有的通道打开都需要关闭 producer.close(); } }
Producer源码
构建—KafkaProducer
- MetricConfig
- 加载负载均衡器
- 初始化Serializer
- 初始化RecordAccumulator——类似于计数器
- 启动newSender——守护线程
public class KafkaProducer<K, V> implements Producer<K, V> {
KafkaProducer(Map<String, Object> configs, Serializer<K> keySerializer, Serializer<V> valueSerializer, ProducerMetadata metadata, KafkaClient kafkaClient, ProducerInterceptors interceptors, Time time) {
ProducerConfig config = new ProducerConfig(ProducerConfig.addSerializerToConfig(configs, keySerializer, valueSerializer));
try {
Map<String, Object> userProvidedConfigs = config.originals();
this.producerConfig = config;
this.time = time;
String transactionalId = userProvidedConfigs.containsKey("transactional.id") ? (String)userProvidedConfigs.get("transactional.id") : null;
this.clientId = buildClientId(config.getString("client.id"), transactionalId);
LogContext logContext;
if (transactionalId == null) {
logContext = new LogContext(String.format("[Producer clientId=%s] ", this.clientId));
} else {
logContext = new LogContext(String.format("[Producer clientId=%s, transactionalId=%s] ", this.clientId, transactionalId));
}
this.log = logContext.logger(KafkaProducer.class);
this.log.trace("Starting the Kafka producer");
Map<String, String> metricTags = Collections.singletonMap("client-id", this.clientId);
// 1. MetricConfig
MetricConfig metricConfig = (new MetricConfig()).samples(config.getInt("metrics.num.samples")).timeWindow(config.getLong("metrics.sample.window.ms"), TimeUnit.MILLISECONDS).recordLevel(RecordingLevel.forName(config.getString("metrics.recording.level"))).tags(metricTags);
List<MetricsReporter> reporters = config.getConfiguredInstances("metric.reporters", MetricsReporter.class, Collections.singletonMap("client.id", this.clientId));
reporters.add(new JmxReporter("kafka.producer"));
this.metrics = new Metrics(metricConfig, reporters, time);
// 2. 加载负载均衡器
this.partitioner = (Partitioner)config.getConfiguredInstance("partitioner.class", Partitioner.class);
long retryBackoffMs = config.getLong("retry.backoff.ms");
if (keySerializer == null) {
this.keySerializer = (Serializer)config.getConfiguredInstance("key.serializer", Serializer.class);
this.keySerializer.configure(config.originals(), true);
} else {
config.ignore("key.serializer");
this.keySerializer = keySerializer;
}
// 3. 初始化Serializer
if (valueSerializer == null) {
this.valueSerializer = (Serializer)config.getConfiguredInstance("value.serializer", Serializer.class);
this.valueSerializer.configure(config.originals(), false);
} else {
config.ignore("value.serializer");
this.valueSerializer = valueSerializer;
}
userProvidedConfigs.put("client.id", this.clientId);
ProducerConfig configWithClientId = new ProducerConfig(userProvidedConfigs, false);
List<ProducerInterceptor<K, V>> interceptorList = configWithClientId.getConfiguredInstances("interceptor.classes", ProducerInterceptor.class);
if (interceptors != null) {
this.interceptors = interceptors;
} else {
this.interceptors = new ProducerInterceptors(interceptorList);
}
ClusterResourceListeners clusterResourceListeners = this.configureClusterResourceListeners(keySerializer, valueSerializer, interceptorList, reporters);
this.maxRequestSize = config.getInt("max.request.size");
this.totalMemorySize = config.getLong("buffer.memory");
this.compressionType = CompressionType.forName(config.getString("compression.type"));
this.maxBlockTimeMs = config.getLong("max.block.ms");
this.transactionManager = configureTransactionState(config, logContext, this.log);
int deliveryTimeoutMs = configureDeliveryTimeout(config, this.log);
this.apiVersions = new ApiVersions();
// 4. 初始化RecordAccumulator——类似于计数器
this.accumulator = new RecordAccumulator(logContext, config.getInt("batch.size"), this.compressionType, lingerMs(config), retryBackoffMs, deliveryTimeoutMs, this.metrics, "producer-metrics", time, this.apiVersions, this.transactionManager, new BufferPool(this.totalMemorySize, config.getInt("batch.size"), this.metrics, time, "producer-metrics"));
List<InetSocketAddress> addresses = ClientUtils.parseAndValidateAddresses(config.getList("bootstrap.servers"), config.getString("client.dns.lookup"));
if (metadata != null) {
this.metadata = metadata;
} else {
this.metadata = new ProducerMetadata(retryBackoffMs, config.getLong("metadata.max.age.ms"), logContext, clusterResourceListeners, Time.SYSTEM);
this.metadata.bootstrap(addresses, time.milliseconds());
}
this.errors = this.metrics.sensor("errors");
// 5. 启动newSender——守护线程
this.sender = this.newSender(logContext, kafkaClient, this.metadata);
String ioThreadName = "kafka-producer-network-thread | " + this.clientId;
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();
config.logUnused();
AppInfoParser.registerAppInfo("kafka.producer", this.clientId, this.metrics, time.milliseconds());
this.log.debug("Kafka producer started");
} catch (Throwable var23) {
this.close(Duration.ofMillis(0L), true);
throw new KafkaException("Failed to construct kafka producer", var23);
}
}
}
Producer是线程安全的
Producer并不是接到一条发一条,是批量发送
发送—producer.send(record)
- 计算分区:消息具体进入哪一个partition
- 计算批次:accumulator.append
- 主要内容:创建批次;向批次中追加消息
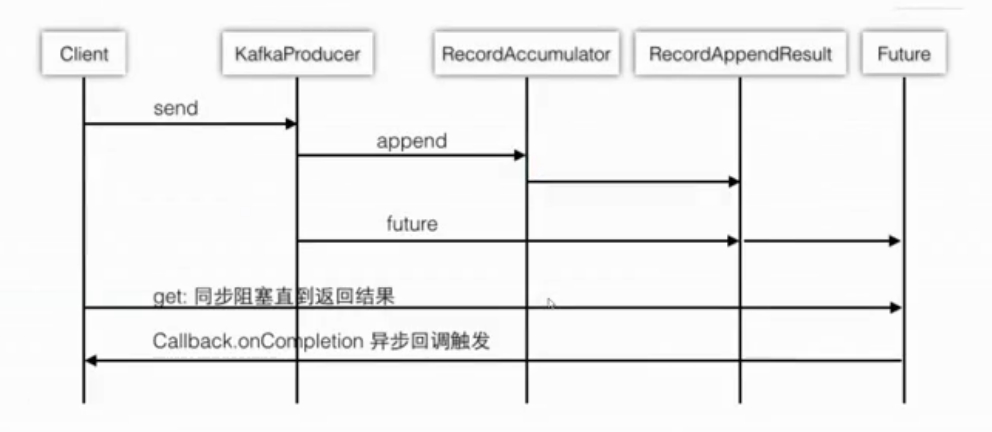
public class KafkaProducer<K, V> implements Producer<K, V> {
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
this.throwIfProducerClosed();
KafkaProducer.ClusterAndWaitTime clusterAndWaitTime;
try {
clusterAndWaitTime = this.waitOnMetadata(record.topic(), record.partition(), this.maxBlockTimeMs);
} catch (KafkaException var20) {
if (this.metadata.isClosed()) {
throw new KafkaException("Producer closed while send in progress", var20);
}
throw var20;
}
long remainingWaitMs = Math.max(0L, this.maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
byte[] serializedKey;
try {
serializedKey = this.keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException var19) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() + " to class " + this.producerConfig.getClass("key.serializer").getName() + " specified in key.serializer", var19);
}
byte[] serializedValue;
try {
serializedValue = this.valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException var18) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() + " to class " + this.producerConfig.getClass("value.serializer").getName() + " specified in value.serializer", var18);
}
// 计算分区:消息具体进入哪一个partition
int partition = this.partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
this.setReadOnly(record.headers());
Header[] headers = record.headers().toArray();
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(this.apiVersions.maxUsableProduceMagic(), this.compressionType, serializedKey, serializedValue, headers);
this.ensureValidRecordSize(serializedSize);
long timestamp = record.timestamp() == null ? this.time.milliseconds() : record.timestamp();
if (this.log.isTraceEnabled()) {
this.log.trace("Attempting to append record {} with callback {} to topic {} partition {}", new Object[]{record, callback, record.topic(), partition});
}
Callback interceptCallback = new KafkaProducer.InterceptorCallback(callback, this.interceptors, tp);
if (this.transactionManager != null && this.transactionManager.isTransactional()) {
this.transactionManager.failIfNotReadyForSend();
}
// 计算批次:accumulator.append
RecordAppendResult result = this.accumulator.append(tp, timestamp, serializedKey, serializedValue, headers, interceptCallback, remainingWaitMs, true);
// 主要内容:创建批次
if (result.abortForNewBatch) {
int prevPartition = partition;
this.partitioner.onNewBatch(record.topic(), cluster, partition);
partition = this.partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
if (this.log.isTraceEnabled()) {
this.log.trace("Retrying append due to new batch creation for topic {} partition {}. The old partition was {}", new Object[]{record.topic(), partition, prevPartition});
}
interceptCallback = new KafkaProducer.InterceptorCallback(callback, this.interceptors, tp);
result = this.accumulator.append(tp, timestamp, serializedKey, serializedValue, headers, interceptCallback, remainingWaitMs, false);
}
if (this.transactionManager != null && this.transactionManager.isTransactional()) {
this.transactionManager.maybeAddPartitionToTransaction(tp);
}
if (result.batchIsFull || result.newBatchCreated) {
this.log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
// 主要内容:向批次中追加消息
this.sender.wakeup();
}
return result.future;
} catch (ApiException var21) {
this.log.debug("Exception occurred during message send:", var21);
if (callback != null) {
callback.onCompletion((RecordMetadata)null, var21);
}
this.errors.record();
this.interceptors.onSendError(record, tp, var21);
return new KafkaProducer.FutureFailure(var21);
} catch (InterruptedException var22) {
this.errors.record();
this.interceptors.onSendError(record, tp, var22);
throw new InterruptException(var22);
} catch (BufferExhaustedException var23) {
this.errors.record();
this.metrics.sensor("buffer-exhausted-records").record();
this.interceptors.onSendError(record, tp, var23);
throw var23;
} catch (KafkaException var24) {
this.errors.record();
this.interceptors.onSendError(record, tp, var24);
throw var24;
} catch (Exception var25) {
this.interceptors.onSendError(record, tp, var25);
throw var25;
}
}
}
Producer发送原理解析
- 直接发送
- 负载均衡
- 异步发送
Producer自定义Partition负载均衡
public class SamplePartition implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
/*
key-1 key-2 key-3
*/
String keyStr = key + "";
String keyInt = keyStr.substring(4);
System.out.println("keyStr : "+keyStr + "keyInt : "+keyInt);
int i = Integer.parseInt(keyInt);
return i%2;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
public class ProducerSample {
private final static String TOPIC_NAME="jiangzh-topic";
public static void main(String[] args) throws ExecutionException, InterruptedException {
// Producer异步发送带回调函数和Partition负载均衡
producerSendWithCallbackAndPartition();
}
/*
Producer异步发送带回调函数和Partition负载均衡
*/
public static void producerSendWithCallbackAndPartition(){
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.220.128:9092");
properties.put(ProducerConfig.ACKS_CONFIG,"all");
properties.put(ProducerConfig.RETRIES_CONFIG,"0");
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,"16384");
properties.put(ProducerConfig.LINGER_MS_CONFIG,"1");
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,"33554432");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.imooc.jiangzh.kafka.producer.SamplePartition");
// Producer的主对象
Producer<String,String> producer = new KafkaProducer<>(properties);
// 消息对象 - ProducerRecoder
for(int i=0;i<10;i++){
ProducerRecord<String,String> record =
new ProducerRecord<>(TOPIC_NAME,"key-"+i,"value-"+i);
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
System.out.println(
"partition : "+recordMetadata.partition()+" , offset : "+recordMetadata.offset());
}
});
}
// 所有的通道打开都需要关闭
producer.close();
}
}
Producer发送消息传递保障
- 最多一次:收到0到1次
- 至少一次:收到1到多次
- 正好一次:有且仅有一次
Producer发送-项目应用
请求参数实例:
{
templateId:"001",
result:[
{"questionId":"1","question":"今天几号","answer":"A"},
{"questionId":"2","question":"你喜爱的颜色","answer":"B"}
]
}
public class KafkaTest {
// kafka producer将数据推送至Kafka Topic
public void templateReported(JSONObject reportInfo) {
log.info("templateReported : [{}]", reportInfo);
String topicName = "hefery-topic";
// 发送Kafka数据
String templateId = reportInfo.getString("templateId");
JSONArray reportData = reportInfo.getJSONArray("result");
// 如果templateid相同,后续在统计分析时,可以考虑将相同的id的内容放入同一个partition,便于分析使用
ProducerRecord<String,Object> record = new ProducerRecord<>(topicName,templateId,reportData);
/*
1、Kafka Producer线程安全,建议多线程复用,如果每个线程都创建,出现大量的上下文切换或争抢的情况,影响Kafka效率
2、Kafka Producer的key是一个很重要的内容:
2.1 我们可以根据Key完成Partition的负载均衡
2.2 合理的Key设计,可以让Flink、Spark Streaming之类的实时分析工具做更快速处理
3、ack - all, kafka层面上就已经有了只有一次的消息投递保障,如果想不丢数据,最好自行处理异常
*/
try{
producer.send(record);
}catch (Exception e){
// 将数据加入重发队列, redis,es,...
}
}
}
Consumer APl
Connector API
Streams API
允许应用程序充当流处理器,从一个或多个 Topic 消耗的输入流,并产生一个输出流至一个或多个输出的Topic,有效地变换所述输入流,以输出流
Kafka设计原理
位移主题存的到底是什么格式的消息呢?所谓的消息格式,你可以简单地理解为是一个 KV 对。Key 和 Value 分别表示消息的键值和消息体,在 Kafka 中它们就是字节数组而已。
位移主题的 Key 中应该保存 3 部分内容:<GroupID,主题名,分区号 >
Group ID 吗?没错,就是这个字段,它能够标识唯一的 Consumer Group。
Kafka项目设计
Kafka 保证消息不丢失
首先明确 Kafka 持久化保证的含义和限定条件。再熟练配置 Kafka 无消息丢失参数
Kafka 只对“已提交”的消息(committed message)做有限度的持久化保证
- 已提交的消息:当 Kafka 的若干个 Broker 成功地接收到一条消息并写入到日志文件后,它们会告诉生产者程序这条消息已成功提交。此时,这条消息在 Kafka 看来就正式变为“已提交的消息”
- 有限度的持久化保证:Kafka 不可能保证在任何情况下都做到不丢失消息。举个极端点的例子,如果地球都不存在了,Kafka 还能保存任何消息吗?显然不能!倘若这种情况下你依然还想要 Kafka 不丢消息,那么只能在别的星球部署 Kafka Broker 服务器
生产者程序丢失数据
目前 Kafka Producer 异步发送消息,也就是说如果调用的是 producer.send(msg),那么它通常会立即返回,但此时不能认为消息发送已成功完成。因此如果出现消息丢失,我们无法知晓
如果用这种方式,可能会有哪些因素导致消息没有发送成功呢?
- 网络抖动,导致消息压根就没有发送到 Broker 端
- 消息本身不合格导致 Broker 拒绝接收(消息太大了,超过了 Broker 的承受能力)
这么来看,让 Kafka“背锅”就有点冤枉它了。就像前面说过的,Kafka 不认为消息是已提交的,因此也就没有 Kafka 丢失消息这一说了
Producer 永远要使用带有回调通知的发送 API,也就是说不要使用 producer.send(msg),而要使用 producer.send(msg, callback)。不要小瞧这里的 callback(回调),它能准确地告诉你消息是否真的提交成功了。一旦出现消息提交失败的情况,你就可以有针对性地进行处理。举例来说,如果是因为那些瞬时错误,那么仅仅让 Producer 重试就可以了;如果是消息不合格造成的,那么可以调整消息格式后再次发送。总之,处理发送失败的责任在 Producer端而非 Broker 端
消费者程序丢失数据
Consumer 端丢失数据主要体现在 Consumer 端要消费的消息不见了。
Consumer 程序有个“位移”的概念,表示的是这个 Consumer 当前消费到的 Topic 分区的位置。下面这张图来自于官网,它清晰地展示了 Consumer 端的位移数据。比如对于 Consumer A 而言,它当前的位移值就是 9;Consumer B 的位移值是 11。这里的“位移”类似于我们看书时使用的书签,它会标记我们当前阅读了多少页,下次翻书的时候我们能直接跳到书签页继续阅读。正确使用书签有两个步骤:第一步是读书,第二步是更新书签页。如果这两步的顺序颠倒了,就可能出现这样的场景:当前的书签页是第 90 页,我先将书签放到第 100 页上,之后开始读书。当阅读到第 95 页时,我临时有事中止了阅读。那么问题来了,当我下次直接跳到书签页阅读时,我就丢失了第 96~99 页的内容,即这些消息就丢失了
Kafka 中 Consumer 端的消息丢失就是这么一回事。要对抗这种消息丢失,办法很简单:维持先消费消息(阅读),再更新位移(书签)的顺序即可。这样就能最大限度地保证消息不丢失。这种处理方式可能带来的问题是消息的重复处理,类似于同一页书被读了很多遍,但这不属于消息丢失的情形
Consumer 程序从 Kafka 获取到消息后开启了多个线程异步处理消息,而 Consumer 程序自动地向前更新位移。假如其中某个线程运行失败了,它负责的消息没有被成功处理,但位移已经被更新了,因此这条消息对于 Consumer 而言实际上是丢失了。关键在于 Consumer 自动提交位移。这个问题的解决方案也很简单:如果是多线程异步处理消费消息,Consumer 程序不要开启自动提交位移,而是要应用程序手动提交位移。单个Consumer 程序使用多线程来消费消息说起来容易,写成代码却异常困难,因为你很难正确地处理位移的更新,也就是说避免无消费消息丢失很简单,但极易出现消息被消费了多次的情况。
最佳实践
- 消息生产者发送消息不要使用 producer.send(msg),而要使用 producer.send(msg, callback)。记住,一定要使用带有回调通知的 send 方法
- 设置 acks = all。acks 是 Producer 的一个参数,代表了你对“已提交”消息的定义。如果设置成 all,则表明所有副本 Broker 都要接收到消息,该消息才算是“已提交”。这是最高等级的“已提交”定义
- 设置 retries 为一个较大的值。这里的 retries 同样是 Producer 的参数,对应前面提到的 Producer 自动重试。当出现网络的瞬时抖动时,消息发送可能会失败,此时配置了retries > 0 的 Producer 能够自动重试消息发送,避免消息丢失
- 设置 unclean.leader.election.enable = false。这是 Broker 端的参数,它控制的是哪些 Broker 有资格竞选分区的 Leader。如果一个 Broker 落后原先的 Leader 太多,那么它一旦成为新的 Leader,必然会造成消息的丢失。故一般都要将该参数设置成 false,即不允许这种情况的发生
- 设置 replication.factor >= 3。这也是 Broker 端的参数。其实这里想表述的是,最好将消息多保存几份,毕竟目前防止消息丢失的主要机制就是冗余
- 设置 min.insync.replicas > 1。这依然是 Broker 端参数,控制的是消息至少要被写入到多少个副本才算是“已提交”。设置成大于 1 可以提升消息持久性。在实际环境中千万不要使用默认值 1
- 确保 replication.factor > min.insync.replicas。如果两者相等,那么只要有一个副本挂机,整个分区就无法正常工作了。我们不仅要改善消息的持久性,防止数据丢失,还要在不降低可用性的基础上完成。推荐设置成 replication.factor = min.insync.replicas +1
- 确保消息消费完成再提交。Consumer 端有个参数 enable.auto.commit,最好把它设置成 false,并采用手动提交位移的方式。就像前面说的,这对于单 Consumer 多线程处理的场景而言是至关重要的
Kafka 拦截器
Kafka 拦截器可以应用于包括客户端监控、端到端系统性能检测、消息审计等多种功能在内的场景
生产者拦截器
在发送消息前以及消息提交成功后植入你的拦截器逻辑
- 在 Producer 端设置参数 interceptor.classes
Properties props = new Properties(); List<String> interceptors = new ArrayList<>(); interceptors.add("com.hefery.kafkaproject.interceptors.AddTimestampInterceptor"); interceptors.add("com.hefery.kafkaproject.interceptors.UpdateCounterInterceptor"); props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors); - 编写的所有Producer 端拦截器都要实现 org.apache.kafka.clients.producer.ProducerInterceptor 接口。该接口是 Kafka 提供的,里面有两个核心的方法
- onSend:在消息发送之前被调用。在发送之前对消息“美美容”
- onAcknowledgement:在消息成功提交或发送失败之后被调用。onAcknowledgement 的调用要早于发送回调通知 callback 的调用。值得注意的是这个方法和 onSend 不是在同一个线程中被调用的,因此如果在这两个方法中调用了某个共享可变对象,一定要保证线程安全。这个方法处在 Producer 发送的主路径中,最好别放太重的逻辑进去,否则 Producer TPS 直线下降
指定拦截器类时要指定它们的全限定名
消费者拦截器
在消费消息前以及提交位移后编写特定逻辑
- 编写的所有Producer 端拦截器都要实现org.apache.kafka.clients..consumer.ConsumerInterceptor 接口。该接口是 Kafka 提供的,里面有两个核心的方法
- onConsume:在消息返回给 Consumer 程序之前调用。也就是说在开始正式处理消息之前,拦截器会先拦一道,搞一些事情,之后再返回给你
- onCommit:Consumer 在提交位移之后调用该方法。通常可以在该方法中做一些记账类的动作,比如记录日志等
指定拦截器类时要指定它们的全限定名
Kafka 消息交付可靠性保障
消息交付可靠性保障,是指 Kafka 对 Producer 和Consumer 要处理的消息提供什么样的承诺
- 最多一次(at most once):消息可能会丢失,但绝不会被重复发送
- 至少一次(at least once):消息不会丢失,但有可能被重复发送
- 精确一次(exactly once):消息不会丢失,也不会被重复发送
Kafka默认的是 至少一次(at least once)
消息成功“提交”,但 Broker 的应答没有成功发送回 Producer端(比如网络出现瞬时抖动),那么 Producer 就无法确定消息是否真的提交成功了。因此,它只能选择重试,也就是再次发送相同的消息。这就是 Kafka 默认提供至少一次可靠性保障的原因,不过这会导致消息重复发送。也可以提供最多一次交付保障,只需要让 Producer禁止重试即可。这样一来,消息要么写入成功,要么写入失败,但绝不会重复发送。我们通常不会希望出现消息丢失的情况,但一些场景里偶发的消息丢失其实是被允许的,相反,消息重复是绝对要避免的。此时,使用最多一次交付保障就是最恰当的。无论是至少一次还是最多一次,都不如精确一次,即消息既不会丢失,也不会被重复处理。或者说,即使Producer 端重复发送了相同的消息,Broker 端也能做到自动去重。在下游 Consumer 看来,消息依然只有一条
Kafka 是怎么做到精确一次的呢?
-
幂等性:Idempotence,最大的优势在于我们可以安全地重试任何幂等性操作,反正它们也不会破坏我们的系统状态幂等性 Producer:仅需要设置一个参数即可,即
props.put("enable.idempotence",ture)或props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG,true)。Producer 自动升级成幂等性 Producer,其他所有的代码逻辑都不需要改变。Kafka 自动帮你做消息的重复去重。在Broker 端多保存一些字段。当 Producer 发送了具有相同字段值的消息后,Broker 能够自动知晓这些消息已经重复了,于是可以在后台默默地把它们“丢弃”掉。幂等性 Producer 的作用范围:首先,它只能保证单分区上的幂等性,即一个幂等性Producer 能够保证某个主题的一个分区上不出现重复消息,它无法实现多个分区的幂等性。其次,它只能实现单会话上的幂等性,不能实现跨会话的幂等性。这里的会话,你可以理解为 Producer 进程的一次运行。当你重启了Producer 进程之后,这种幂等性保证就丧失了 -
事务:Transaction,实现多分区以及多会话上的消息无重复设置事务型 Producer:开启
enable.idempotence=true以及设置 Producer 端参数transctional.id。最好为其设置一个有意义的名字,编码也要变化// 事务的初始化 producer.initTransactions(); try { // 事务开始 producer.beginTransaction(); producer.send(record1); producer.send(record2); // 事务提交 producer.commitTransaction(); } catch (KafkaException e) { // 事务终止 producer.abortTransaction(); }这段代码能够保证 Record1 和 Record2 被当作一个事务统一提交到 Kafka,要么它们全部提交成功,要么全部写入失败。实际上即使写入失败,Kafka 也会把它们写入到底层的日志中,也就是说 Consumer 还是会看到这些消息。因此在 Consumer 端,读取事务型 Producer 发送的消息也是需要一些变更的。修改起来也很简单,设置 isolation.level参数的值即可。当前这个参数有两个取值:
read_uncommitted:这是默认值,表明 Consumer 能够读取到 Kafka 写入的任何消息,不论事务型 Producer提交事务还是终止事务,其写入的消息都可以读取。很显然,如果你用了事务型 Producer,那么对应的Consumer 就不要使用这个值;read_committed:表明 Consumer 只会读取事务型Producer 成功提交事务写入的消息。当然,也能看到非事务型 Producer 写入的所有消息