
Spring Data JPA简介
JPA:Java Persistence API,用于对象持久化的API。JPA是规范:JPA本质上就是一种ORM规范,不是ORM框架——因为JPA并未提供ORM实现。基于ORM的规范,内部是由一系列的接口和抽象类构成,它只是制订了一些规范,提供了一些编程的API接口,但具体实现则由ORM厂商提供实现
JPA 通过 JDK 5.0 注解描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中
Spring Data JPA 是 Spring 基于 ORM 框架、JPA 规范的基础上封装的一套JPA应用框架,可使开发者用极简的代码即可实现对数据库的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展
Spring Data JPA 让我们解脱了 DAO 层的操作,基本上所有CRUD都可以依赖于它来实现,在实际的工作工程中,推荐使用Spring Data JPA + ORM(如:hibernate)完成操作,这样在切换不同的ORM框架时提供了极大的方便,同时也使数据库层操作更加简单,方便解耦
Spring Data JPA与JPA和Hibernate的关系
- JPA是一套规范,内部由接口和抽象类组成,底层需要 Hibernate 作为其实现类完成数据持久化工作
- Hibernate是一套成熟的 ORM 开放源代码的对象关系映射框架,将 POJO 与数据库表建立映射关系,而且 Hibernate 实现了 JPA 规范,所以也可以称 Hibernate 为 JPA的一种实现方式,我们使用 JPA 的 API 编程,意味着站在更高的角度上看待问题(面向接口编程)。Hibernate 可以自动生成 SQL 语句,自动执行,使得 Java 程序员可以随心所欲的使用对象编程思维来操纵数据库
- Spring Data JPA是 Spring 提供的一套对 JPA 操作更加高级的封装,是在 JPA 规范下的专门用来进行数据持久化的解决方案

Spring Data JPA注解
注解扫描
SpringBoot中默认情况下,当 Entity 类、Repository 类与主类在同一个包下或在主类所在包的子类时,Entity 类、Repository 类会被自动扫描到并注册到 Spring 容器,此时使用者无需任何额外配置。当不在同一包或不在子包下时,需要分别通过在主类上加注解@EntityScan( basePackages = {"xxx.xxx"})、 @EnableJpaRepositories( basePackages = {"xxx.xxx"})注解来分别指定 Entity、Repository 类位置
可多处使用 @EntityScan:它们的 basePackages 可有交集,但必须覆盖到所有被 Resository 使用到的Entity否则会报错。可多处使用@EnableJpaRepositories:它们的 basePackages 不能有交集否则会报重复定义的错(除非配置允许覆盖定义),必须覆盖到所有被使用到的 Resository
注解使用
实体类注解
- @Entity:指定当前类为实体类
- @Table:指定实体类与数据库表映射关系
- schema:数据库名
- name:数据库表名
实体类属性
- @Id:当前主键字段
- @GeneratedValue:
- strategy:主键生成策略
- GenerationType.AUTO:auto_increment
- GenerationType.IDENTITY:表自增长,不支持Oracle
- GenerationType.SEQUENCE:序列生成主键,不支持MySQL
- GenerationType.TABLE:数据库表生成主键,框架借由表模拟序列生成主键
- strategy:主键生成策略
- @Column:建立实体类属性与数据库表字段映射关系,无此字段也会将字段映射到表列。当实体的属性与其映射的数据库表的列不同名时需要使用 @Column 标注说明
- name:指定映射的数据库表字段
- unique:是否唯一
- nullable:是否为空
- insertable:是否可插入
- updatable:是否可更新
- @Convert(converter = UserStatus.class):Entity中将任意对象映射为一个数据库字段
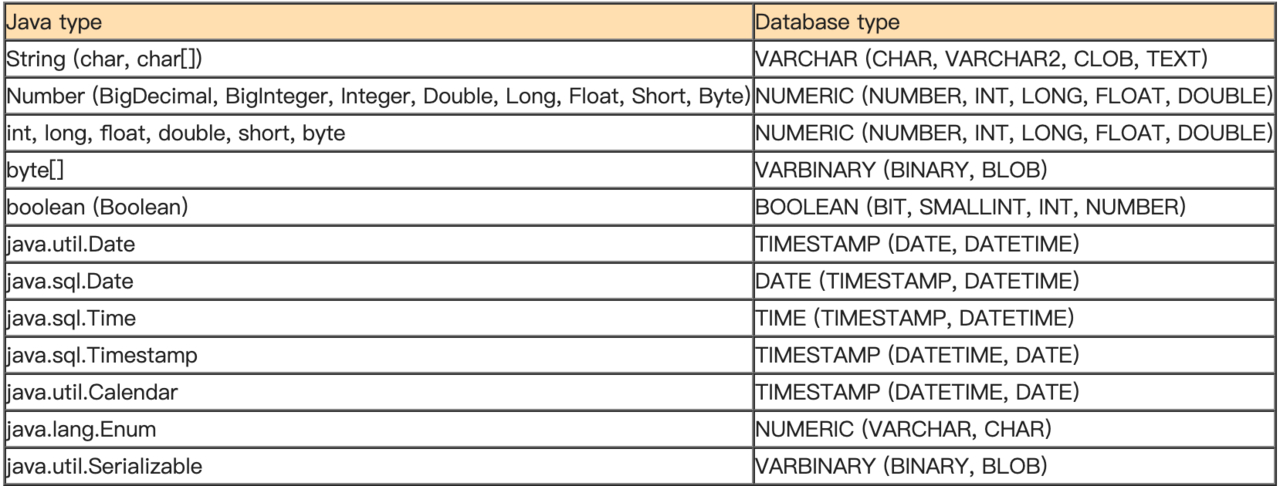
JPA对象属性与数据库列的映射
Spring Data JPA配置
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/hefery_test?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC
username: root
password: 123456
jpa:
hibernate:
# 配置是否开启自动更新数据库表结构
# create:每次加载hibernate时,先删除已存在的数据库表结构再重新生成
# create-drop:每次加载hibernate时,先删除已存在的数据库表结构再重新生成,并且当 sessionFactory关闭时自动删除生成的数据库表结构
# update:只在第一次加载hibernate时自动生成数据库表结构,以后再次加载hibernate时根据model类自动更新表结构
# validate:每次加载hibernate时,验证数据库表结构,只会和数据库中的表进行比较,不会创建新表,但是会插入新值
# none:关闭自动更新
ddl-auto: update
# 控制台打印SQL
show-sql: true
properties:
# 控制台打印SQL
hibernate.show_sql: true
# 控制台打印的SQL格式化
hibernate.format_sql: true
open-in-view: false
Spring Data JPA原理
JPA命名查询原理
方法名解析原理:方法名中除了保留字(findBy、top、within等)外的部分以 and 为分隔符提取出条件单词,然后解析条件获取各个单词并看是否和 Entity 中的属性对应(不区分大小写进行比较)
get/find 与 by之间的字段会被忽略:getNameById == getById,会根据 id 查出整个Entity而不会只查 name 字段
查询条件解析原理:假设 School 和 Student 是一对多关系,Student 有所属School school 字段、School 有 String addressCode 属性。Studetn getByNameAndSchoolAddressCode(String studentName, String addressCode)JPA会自动生成条件 studentName 和关联条件 student.school.addressCode 进行查询
- 由 And 分割得到 studentName、SchoolAddressCode
- 分别看 Student 中是否有上述两属性,显然前者有后者无,则后者需要进一步解析
- JPA 按驼峰命名格式从后往前尝试分解 SchoolAddressCode:先得到 [SchoolAdress、Code],由于 Student 没有 SchoolAddress 属性故继续尝试分解,得到 [School、AdressCode];由于Student 有 School 属性且 School 有 addressCode 属性故满足,最终得到条件student.school.addressCode。注:但若 Student 中有 SchoolAdress schoolAddress 属性但schoolAddress 中没有 code 属性,则会因找不到 student.schoolAdress.code 而报错,所以可通过下划线显示指定分割关系,即写成:
getByNameAndSchool_AddressCode
查询字段解析原理:默认会查出 Entity 的所有字段且返回类型为该 Entity 类型,有两种情况可查询部分字段(除此外都查出所有字段):
- 通过 @Query 实现自定义查询逻辑中只查部分字段
- 返回类型为自定义接口或该接口列表,接口中仅包含部分字段的 getter
在查询时,通常需要同时根据多个属性进行查询,且查询的条件也格式各样(大于某个值、在某个范围等等),Spring Data JPA 为此提供了一些表达条件查询的关键字
| 查询关键字 | SQL关键字 | 说明 |
|---|---|---|
| And | AND | findByUsernameAndPassword(String username, String password) |
| Or | OR | findByUsernameOrAddress(String username, String address) |
| Between | Between | findBySalaryBetween(int max, int min) |
| LessThan | < | findBySalaryLessThan(int max) |
| GreaterThan | > | findBySalaryGreaterThan(int min) |
| IsNull | IS NULL | findByUsernameIsNull(String username) |
| IsNotNull | IS NOT NULL | findByUsernameIsNotNull(String username) |
| NotNull | NOT NULL | findByUsernameNotNull(String username) |
| Like | LIKE | findByUsernameLike(String username) |
| NotLike | NOT LIKE | findByUsernameNotLike(String username) |
| OrderBy | ORDER BY | findByUsernameOrderBySalaryAsc(String username) |
| Not | NOT | findByUsernameNot(String username) |
| In | IN | findByUsernameIn(Collection\<String> userList) |
| NotIn | NOT IN | findByUsernameNotIn(Collection\<String> userList) |
| Containing | 包含指定字符串 | |
| StargingWith | 以指定字符串开头 | |
| EndingWith | 以指定字符串结尾 | |
| IgnoreCase | findByUsernameIgnoreCase(String username) |
Spring Data JPA实战
<!-- Java Persistence API, ORM 规范 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- MySQL 驱动, 注意, 这个需要与 MySQL 版本对应 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.46</version>
<scope>runtime</scope>
</dependency>
Spring Data JPA增删改查
编写商品实体类
创建商品数据库表
CREATE TABLE `t_ecommerce_goods` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`goods_category` varchar(64) NOT NULL DEFAULT '' COMMENT '商品类别',
`brand_category` varchar(64) NOT NULL DEFAULT '' COMMENT '品牌分类',
`goods_name` varchar(64) NOT NULL DEFAULT '' COMMENT '商品名称',
`goods_pic` varchar(256) NOT NULL DEFAULT '' COMMENT '商品图片',
`goods_description` varchar(512) NOT NULL DEFAULT '' COMMENT '商品描述信息',
`goods_status` int(11) NOT NULL DEFAULT '0' COMMENT '商品状态',
`price` int(11) NOT NULL DEFAULT '0' COMMENT '商品价格',
`supply` bigint(20) NOT NULL DEFAULT '0' COMMENT '总供应量',
`inventory` bigint(20) NOT NULL DEFAULT '0' COMMENT '库存',
`goods_property` varchar(1024) NOT NULL DEFAULT '' COMMENT '商品属性',
`create_time` datetime NOT NULL DEFAULT '0000-01-01 00:00:00' COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT '0000-01-01 00:00:00' COMMENT '更新时间',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `goods_category_brand_name` (`goods_category`,`brand_category`,`goods_name`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=16 DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='商品表';
创建商品的实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
@Entity
@EntityListeners(AuditingEntityListener.class)
@Table(name = "t_ecommerce_goods")
public class EcommerceGoods {
/** 自增主键 */
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", nullable = false)
private Long goodsId;
/** 商品类型 */
@Column(name = "goods_category", nullable = false)
@Convert(converter = GoodsCategoryConverter.class)
private GoodsCategory goodsCategory;
/** 品牌分类 */
@Column(name = "brand_category", nullable = false)
@Convert(converter = BrandCategoryConverter.class)
private BrandCategory brandCategory;
/** 商品名称 */
@Column(name = "goods_name", nullable = false)
private String goodsName;
/** 商品名称 */
@Column(name = "goods_pic", nullable = false)
private String goodsPic;
/** 商品描述信息 */
@Column(name = "goods_description", nullable = false)
private String goodsDescription;
/** 商品状态 */
@Column(name = "goods_status", nullable = false)
@Convert(converter = GoodsStatusConverter.class)
private GoodsStatus goodsStatus;
/** 商品价格: 单位: 分、厘 */
@Column(name = "price", nullable = false)
private Integer price;
/** 总供应量 */
@Column(name = "supply", nullable = false)
private Long supply;
/** 库存 */
@Column(name = "inventory", nullable = false)
private Long inventory;
/** 商品属性, json 字符串存储 */
@Column(name = "goods_property", nullable = false)
private String goodsProperty;
/** 创建时间 */
@CreatedDate
@Column(name = "create_time", nullable = false)
private Date createTime;
/** 更新时间 */
@LastModifiedDate
@Column(name = "update_time", nullable = false)
private Date updateTime;
}
创建商品Dao接口
只需要编写 Dao 层接口,不需要编写 Dao 层接口的实现类
@Repository
public interface EcommerceGoodsDao extends PagingAndSortingRepository<EcommerceGoods, Long> {
}
Dao接口规范
-
需要继承
JpaRepository或PagingAndSortingRepository,并提供数据库表的主键相应泛型 -
update 和 delete 加 @Transactional、@Modefying
@Transactional @Modifying @Query("delete from EngineerServices es where es.engineerId = ?1") int deleteByEgId(String engineerId); -
JPA的 update 操作
- Repository 中 @Modifying + @Query
- Repository 的 save 方法:JPA会判根据 Entity 的主键判断该执行 insert 还是 update,若没指定主键或数据库中不存在该主键的记录则执行 update。此法在通过在 Entity 指定 @Where 实现了软删除的情况下行不通,因为 JPA 通过内部执行查询操作判断是否是 update 时查询操作也被加上了 @Where,从而查不到数据而被,进而最终执行 insert,此时显然报主键冲突;先通过 Repository 查出来,修改后再执行 save,这样能确保为 update 操作
Dao继承的类
JpaRepository
JpaRepository<操作实体类类型, 实体类主键属性>,继承PagingAndSortingRepository<T, ID>
@NoRepositoryBean
public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
// 查询所有实体
List<T> findAll();
// 查询所有实体并排序
List<T> findAll(Sort sort);
// 根据ID集合查询实体
List<T> findAllById(Iterable<ID> ids);
// 保存并返回修改后的实体集合
<S extends T> List<S> saveAll(Iterable<S> entities);
// 提交事务
void flush();
// 保存实体并立即提交事务
<S extends T> S saveAndFlush(S entity);
<S extends T> List<S> saveAllAndFlush(Iterable<S> entities);
/** @deprecated */
@Deprecated
default void deleteInBatch(Iterable<T> entities) {
this.deleteAllInBatch(entities);
}
// 批量删除实体集合
void deleteAllInBatch(Iterable<T> entities);
void deleteAllByIdInBatch(Iterable<ID> ids);
// 批量删除所有实体
void deleteAllInBatch();
/** @deprecated */
// 根据ID查询实体
@Deprecated
T getOne(ID id);
T getById(ID id);
// 查询与指定Example匹配的所有实体
<S extends T> List<S> findAll(Example<S> example);
// 查询与指定Example匹配的所有实体并排序
<S extends T> List<S> findAll(Example<S> example, Sort sort);
}
findOne()与getOne():findOne立即加载;getOne延迟加载
PagingAndSortingRepository<T, ID>
PagingAndSortingRepository<T, ID>,继承 CrudRepository<T, ID>
@NoRepositoryBean
public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> {
// 排序
Iterable<T> findAll(Sort sort);
// 分页
Page<T> findAll(Pageable pageable);
}
CrudRepository<T, ID>
@NoRepositoryBean
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S entity);
<S extends T> Iterable<S> saveAll(Iterable<S> entities);
Optional<T> findById(ID id);
boolean existsById(ID id);
Iterable<T> findAll();
Iterable<T> findAllById(Iterable<ID> ids);
long count();
void deleteById(ID id);
void delete(T entity);
void deleteAllById(Iterable<? extends ID> ids);
void deleteAll(Iterable<? extends T> entities);
void deleteAll();
}
商品Service接口及实现类
- 增:save
- 删:delete
- 改:save
- 查:find
public interface IGoodsService {
/** 商品列表查询 */
List<GoodsInfo> getGoodsInfoList();
/** 通过商品编码查询商品信息 */
GoodsInfo getGoodsInfoList(Integer goodsId);
/** 获取分页的商品信息 */
PageSimpleGoodsInfo getSimpleGoodsInfoByPage(int page);
/** 添加商品 */
void saveGoods(GoodsInfo goods);
/** 修改商品信息 */
void updateGoods(GoodsInfo goods);
/** 扣减商品库存 */
Boolean deductGoodsInventory(Integer goodsId);
}
@Slf4j
@Service
@Transactional(rollbackFor = Exception.class)
public class GoodsServiceImpl implements IGoodsService {
private final EcommerceGoodsDao ecommerceGoodsDao;
/** 商品列表查询 */
@Override
public List<GoodsInfoBean> getGoodsInfoList() {
List<GoodsInfo> list = ecommerceGoodsDao.findAll();
if(null != list && list.size() > 0) {
return list;
}
return null;
}
/** 添加商品 */
@Override
public void saveGoods(GoodsInfo goods) {
ecommerceGoodsDao.save(goods);
}
/** 通过商品编码查询商品信息 */
@Override
public GoodsInfo getGoodsInfoByGoodsId(Integer goodsId) {
if(null != goodsId) {
return ecommerceGoodsDao.getOne(goodsId);
}
return null;
}
/** 获取分页的商品信息 */
@Override
PageSimpleGoodsInfo getSimpleGoodsInfoByPage(int page) {
// 分页不能从 redis cache 中去拿
if (page <= 1) {
page = 1; // 默认是第一页
}
// 这里分页的规则(你可以自由修改): 1页10调数据, 按照 id 倒序排列
Pageable pageable = PageRequest.of(
page - 1, 10, Sort.by("id").descending()
);
Page<EcommerceGoods> orderPage = ecommerceGoodsDao.findAll(pageable);
// 是否还有更多页: 总页数是否大于当前给定的页
boolean hasMore = orderPage.getTotalPages() > page;
return new PageSimpleGoodsInfo(
orderPage.getContent().stream().map(EcommerceGoods::toSimple).collect(Collectors.toList()), hasMore
);
}
/** 修改商品信息 */
@Override
public void updateGoods(GoodsInfo goods{
ecommerceGoodsDao.save(bean);
}
/** 扣减商品库存 */
@Override
public void deductGoodsInventory(Integer goodsId) {
ecommerceGoodsDao.delete(goodsId)
}
}
商品Controller注入Service
@Controller
@RequestMapping(value = "/goods")
public class GoodsInfoController {
@Autowired
private IGoodsService goodsInfoService;
/** 查询所有商品信息 */
@RequestMapping(value = "/list")
public ModelAndView queryGoodsInfo() {
ModelAndView modelAndView = new ModelAndView();
modelAndView.setViewName("goodsList");
modelAndView.addObject("goodsList", goodsInfoService.queryGoodsList());
return modelAndView;
}
/** 跳转到商品添加页面 */
@RequestMapping(value = "/toAddGoods")
public ModelAndView toAddGoods() {
ModelAndView modelAndView = new ModelAndView();
modelAndView.setViewName("addGoods");
return modelAndView;
}
/** 添加商品 */
@RequestMapping(value = "/saveGoods", method = RequestMethod.POST)
public String saveGoods(GoodsInfoBean bean) {
try {
goodsInfoService.saveGoods(bean);
} catch (Exception e) {
e.printStackTrace();
}
return "redirect:/goods/list";
}
/** 跳转到商品修改页面,携带数据 */
@RequestMapping(value = "/toUpdateGoods/{goodsNum}",method = RequestMethod.GET)
public ModelAndView toUpdateGoods(@PathVariable("goodsNum") Integer goodsNum) {
ModelAndView modelAndView = new ModelAndView();
modelAndView.setViewName("updateGoods");
modelAndView.addObject("goodsInfo", goodsInfoService.queryGoodsByNum(goodsNum));
return modelAndView;
}
/** 修改商品信息 */
@RequestMapping(value = "/updateGoods",method = RequestMethod.POST)
public String updateGoods(GoodsInfoBean bean) {
try {
goodsInfoService.updateGoods(bean);
} catch (Exception e) {
e.printStackTrace();
}
return "redirect:/goods/list";
}
/** 删除商品 */
@RequestMapping(value = "/deleteGoods/{goodsNum}", method = RequestMethod.GET)
public String deleteGoods(@PathVariable("goodsNum") Integer goodsNum) {
try {
goodsInfoService.deleteGoodsByNum(goodsNum);
} catch (Exception e) {
e.printStackTrace();
}
return "redirect:/goods/list";
}
Spring Data JPA复杂查询
JPQL:Java Persistence Query Language,Java 持久化查询语言(JPQL)旨在以面向对象表达式语言的表达式。语法与 SQL 相似,查询的是类中的属性
public interface UserDao extends JpaRepository<User, Serializable> {
@Query(value = "FROM User WHERE name = ?1")
User findByName(String name);
@Query(value = "FROM User WHERE id = ?1 AND name = ?2")
User findByIdAndName(Integer id, String name);
}
表关系
- 一对一:@OneToOne
- 一对多:@OneToMany
@OneToMany(targetEntity = LinkMan.class) @JoinColumn(name = "外键名称" referencedColumnName = "cust_id") private Set<LinkMan> linkMans = new HashSet<>(); - 多对一:@ManyToOne
@ManyToOne(targetEntity = Customer.class) @JoinColumn(name = "外键名称" referencedColumnName = "cust_id") private Customer customer;
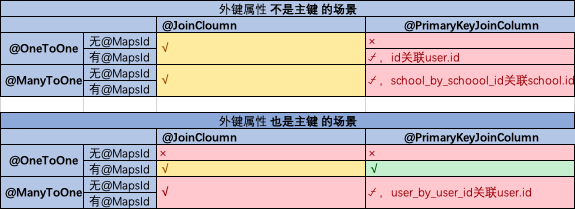
@JoinColumn/@PrimaryKeyJoinColumn、@MapsId
- @JoinColumn用来指定外键,其name属性指定该注解所在Entity对应的表的一个列名
https://www.cnblogs.com/chiangchou/p/mappedBy.html
- 外键属性不是主键的场景(第一种),用 @OneToOne/@ManyToOne + @JoinColumn 即可,为了简洁推荐不用@MapIds,示例见上面的school_id关联school id设置
- 外键属性是主键的场景(第二种),用 @OneToOne + @JoinColumn + @MapsId ,示例见上面的student id关联user id设置
条件查询
模糊查询
对于单字段的可以直接在方法名加Containing
@Query("select s from SchoolEntity s where s.customerId=?1 and (?2 is null or s.name like %?2% or s.bz like %?2% ) ")
List<User> getByUserId(String userId, Pageable pageable);
In查询
@Query( "select * from student where id in ?1", nativeQuery=true)
//@Query( "select s from StudentEntity s where s.id in ?1")
List<StudentEntity> myGetByIdIn(Collection<String> studentIds );//复杂查询,自定义查询逻辑
List<StudentEntity> getByIdIn( Collection<String> studentIds );//简单查询,声明语句即可
查询Entity中的部分字段
- 在 @Query 注解直接写明查询字段。若是查询多个字段则返回时默认将这些字段包装为 Object[]、若返回有多条记录则包装成 List<Object[]>
- 通过方法签名实现只查询部分字段的方法
List<IdAndLanguageType> getLanguagesTypeByCourseIdIn(Collection<String> courseIdCollection),JPA内部将之转成了用@Query 注解的查询- 获得要查询的字段名:idx、languageType
- 生成@Query查询:
@Query(" select new map(idx as idx, languageType as languageType) from CourseEntity where id in ?1 ")
JPA 集合类型查询参数
List<User> getByIdInAndUserId(Collection<Integer> userIdList, Integer userId),关键在于 In 关键字。参数用 Collection 类型,当然也可以用 List、Set 等,但用 Collection 更通用,因为此时实际调用可以传 List、Set 等实参
更新或创建并返回该Entity
如User u = userRepository.save(user) ,Repository 的 save 方法会返回被 save 的 entity,但若是第一次保存该 entity(即新建一条记录)时 u.username 的值会为 null,解决:用 saveAndFlush。在一个事务内,调用 save/saveAndFlush 后再查询出来的数据实际上还是内存的数据(原因在于 save是相对于Persistent Context 而言而非 DB 而言的),因此如果数据库时间字段启用了 CURRENT_TIMESTAMP ON UPDATE,则返回给调用者的时间实际上与数据库中的时间不一样。故最好最好不要用自动更新时间,而是业务逻辑中手动设置更新时间
分页查询
主要看 PagingAndSortingRepository 接口方法参数 Pageable-分页、Sort-排序
@NoRepositoryBean
public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> {
// 排序
Iterable<T> findAll(Sort sort);
// 分页
Page<T> findAll(Pageable pageable);
}
查询方法中,需要传入参数 Pageable ,当查询中有多个参数的时候 Pageable 建议做为最后一个参数传入
Pageable 是 Spring 封装的分页实现类,使用时需要传入页数、每页条数和排序规则
Page<User> findByUserName(String userName,Pageable pageable);
关联查询
关联删除
假设有 user、admin 两表,admin.user_id 与 user.id 对应。当要删除 userId 为"xx" 管理员时:
- 若业务逻辑中未使用 JPA 逻辑删除:
- 若后者通过外键关联前者,则直接从 user 删除 id 为"xx"的记录即可,此时会级联删除 admin表的相应记录。当然要分别从两表删除记录也可,此时须保证先从 admin 表再从 user 表删除
- 若无外键关联,则需要分别从user、admin删除该记录,顺序先后无关紧要
- 若使用了软删除,对于软删除操作外键将不起作用(因为物理上并未删除记录),因此此时也只能分别从两表软删除记录。但不同的是,此时须先从admin再从user表删除记录。若顺序相反,会发现user 表的记录不会被软删除。猜测原因为:内存中存在 userEntity、adminEntity 且adminEntity.userByUserId 引用了userEntity,导致 delete userEntity 时发现其被 adminEntity 引用了从而内部取消执行了delete操作。
在实际业务中一般都会启用逻辑删除,所以物理删除的场景很少
综上在涉及到关联删除时,最好按拓扑排序的顺序(先引用者再被引用者)依次删除各 Entity 记录
级联操作
用于有依赖关系的实体间(@OneToMany、@ManyToOne、@OneToOne)的级联操作:当对一个实体进行某种操作时,若该实体加了与该操作相关的级联标记,则该操作会传播到与该实体关联的实体(即对被级联标记的实体施加某种与级联标记对应的操作时,与该实体相关联的其他实体也会被施加该操作)。包括:
@OneToMany(targetEntity = LinkMan.class, cascade = CascadeType.ALL)
@JoinColumn(name = "外键名称" referencedColumnName = "cust_id")
private Set<LinkMan> linkMans = new HashSet<>();
- CascadeType.PERSIST:持久化,即保存
- CascadeType.REMOVE:删除当前实体时,关联实体也将被删除
- CascadeType.MERGE:更新或查询
- CascadeType.REFRESH:级联刷新,即在保存前先更新别人的修改:如Order、Item被用户A、B同时读出做修改且B的先保存了,在A保存时会先更新Order、Item的信息再保存。
- CascadeType.DETACH:级联脱离,如果你要删除一个实体,但是它有外键无法删除,你就需要这个级联权限了。它会撤销所有相关的外键关联
- CascadeType.ALL:上述所有
注:级联应该标记在One的一方 。如对于 @OneToMany的Person 和 @ManyToOne的Phone,若将CascadeType.REMOVE标记在Phone则删除Phone也会删除Person,显然是错的。慎用CascadeType.ALL,应该根据业务需求选择所需的级联关系,否则可能酿成大祸