
MyBatis简介
基于Java的持久层框架
特点:
- 使用简单的 XML 或注解定制化 SQL,将接口和 POJO 映射成数据库中的记录
MyBatis官网地址:http://www.mybatis.org/mybatis-3/
MyBatis原理
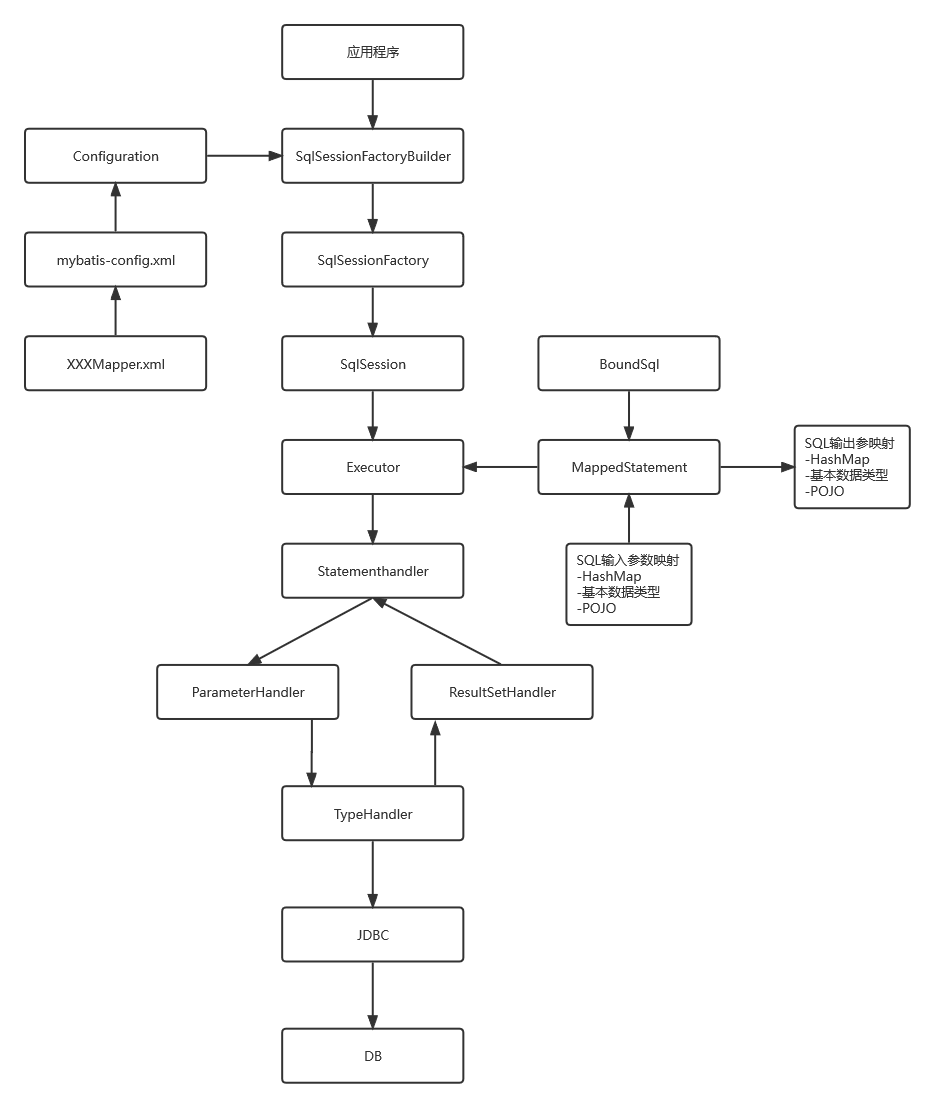
MyBatis核心组件
- SqlSessionFactoryBuilder,构造器,负责构建 SqlSessionFactory
SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(config); - SqlSessionFactory,工厂接口,创建 SqlSession 实例,一旦创建,就会在整个应用运行过程中始终存在
SqlSession session = sessionFactory.openSession(); - SqlSession,会议接口,主要是和数据库进行交互,完成增删改查功能
User user = session.selectOne("user.selectById", 1); - SQLMapper,SQL映射
- Executor:主要负责 SQL 的执行和查询缓存的维护
- StatementHandler:封装 JDBC Statement 操作
- ParameterHandler:负责对用户传递的参数转换成 JDBC Statement 所需要的参数
- ResultSetHandler:负责将 JDBC 返回的 ResultSet 结果集对象转换成 List 类型的集合
- TypeHandler:负责 Java 和 JDBC 数据类型之间的映射和转换
- MappedStatement:MappedStatement 维护一条 <select | update | delete | insert> 节点的封装
- BoundSql:表示动态生成的 SQL 以及参数信息
- Configuration: MyBatis 所有的配置信息都在 Configuration 对象
Mybatis的Executor执行器
- SimpleExecutor:每执⾏⼀次update或select,开启⼀个Statement 对象,⽤完⽴刻关闭Statement对象
- ReuseExecutor:执⾏update或select,以sql作为key查找Statement对象,存在就使⽤,不存在就创建。⽤完后,不关闭Statement对象,⽽是放置于Map<String, Statement>内,供下⼀次使⽤,重复使⽤Statement对象
- BatchExecutor:执⾏update(没有select,JDBC 批处理不⽀持select),将所有sql都添加到批处理中(addBatch()),等待统⼀执⾏(executeBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐⼀执⾏executeBatch()批处理。与JDBC批处理相同
PS:在Mybatis配置⽂件中,可以指定默认的ExecutorType执⾏器类型,也可⼿动DefaultSqlSessionFactory的创建SqlSessio 的⽅法传递ExecutorType类型参数
MyBatis处理流程
MyBatis 应用程序根据 XML 配置文件创建 SqlSessionFactory,SqlSessionFactory 根据配置,配置来源于两个地方,一处是配置文件,一处是 Java 注解,获取 SqlSession。SqlSession 包含了执行 SQL 所需要的所有方法,可以通过 SqlSession 实例直接运行映射的 SQL 语句,完成对数据的增删改查和事务提交等,用完之后关闭 SqlSession
获取数据源
获取执行SQL
操作数据库
MyBatis操作
Mybatis的编程步骤
- 创建 SqlSessionFactory
- 通过 SqlSessionFactory 创建 SqlSession
- 通过 sqlsession 执行数据库操作
- 调用 session.commit() 提交事务
- 调用 session.close() 关闭会话
public class MyBatisUtils {
private static SqlSessionFactory sqlSessionFactory;
// 从 XML 中构建 SqlSessionFactory
static {
try {
// 获取 SqlSessionFactory 对象
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
// 从 SqlSessionFactory 中获取 SqlSession
public static SqlSession getSqlSession() {
// 增删改要设置 openSession 开启 autoCommint 为 true,否则方法执行成功,数据库却并没有改变
return sqlSessionFactory.openSession(true);
}
}
测试 dao 可用性:pojo --> dao -->
|-- 库表:user(id, name, password)
|-- 方法:
|-- List<User> getUserList(); // 查询所有 user
|-- User getUserById(int id); // 根据 id 查找 user
|-- User getUserMapByIdAndName(Map<String, Object> map); // 根据 id 和 name 查找 user
|-- List<User> getUserListByNameLike(String namevalue); // 根据 name 模糊查询相关 user
|-- int insertUser(User user); // 新增 user,使用 User 对象传值
|-- int insertUserMap(Map<String, Object> map); // 新增 user:使用 map 传值
|-- int updateUser(User user); // 修改 User
|-- int deleteUserById(int id); // 根据 id 删除 user
|-- 说明:
|-- 传入多个参数时,MyBatis 会做特殊处理:
|-- 封装成 Map,key[param1...paramN]-value[userId,userName,password]
MyBatis配置文件:mybatis-config.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!-- configuration核心配置-->
<configuration>
<settings>
<!-- 驼峰命名转换 -->
<setting name="mapUnderscoreToCamelCase" value="true"/>
<!-- 控制台打印日志 -->
<setting name="logImpl" value="STDOUT_LOGGING" />
</settings>
<environments default="development">
<!-- 开发环境 -->
<environment id="development">
<!--指定事务管理的类型:Java的JDBC的提交和回滚设置-->
<transactionManager type="JDBC"/>
<!--连接源配置DataSource:POOLED是采用连接池的方式管理数据库的连接-->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai"/>
<property name="username" value="root"/>
<property name="password" value="123456"/>
</dataSource>
</environment>
<!-- 测试环境 -->
<environment id="test">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<!-- 加载映射配置:每个 Mapper.xml 都要在 MyBatis 核心配置文件中注册 -->
<mappers>
<mapper resource="mappers/UserMapper.xml"/>
</mappers>
</configuration>
映射文件UserMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- namespace:接口绑定,输入接口完整限定名-->
<mapper namespace="com.hefery.dao.UserMapper">
<!--
select 标签:
1.id="接口方法名"
2.parameterType="参数的类全限定名或别名" PS:不要写成 parameterMap(废弃)
3.resultType:返回结果的类全限定名或别名,如果返回的是集合,应设置集合包含的类型,而不是集合本身的类型
4.resultMap:对外部 resultMap 的命名引用 PS:resultType 和 resultMap 之间只能同时使用一个
mapper.xml文件中同一命名空间只能有一个唯一的id,导致接口方法只能有唯一的方法名
-->
<select id="getUserList" resultType="com.hefery.pojo.User">
SELECT * FROM user;
</select>
<!-- 使用对象传参,取对象属性-->
<select id="getUserById" parameterType="int" resultType="com.hefery.pojo.User">
SELECT * FROM user WHERE id=#{id};
</select>
<!-- 使用 map 键值对传值,只需要取 key 即可,不需要对表的每个字段都设置 -->
<select id="getUserMapByIdAndName" parameterType="map" resultType="com.hefery.pojo.User">
SELECT * FROM user WHERE id=#{id} AND name=#{username};
</select>
<select id="getUserListByNameLike" resultType="com.hefery.pojo.User">
SELECT * FROM user WHERE name LIKE "%"#{namevalue}"%";
</select>
<!--
insert、update、delete 标签:
1.id="接口方法名"
2.parameterType="参数的类全限定名或别名" PS:不要写成 parameterMap(废弃)
PS:不用返回类型resultType,对象中的属性可以直接取出
-->
<insert id="insertUser" parameterType="com.hefery.pojo.User">
INSERT INTO user(id, name, password) VALUES(#{id}, #{username}, #{password});
</insert>
<insert id="insertUserMap" parameterType="map">
INSERT INTO user(id, name, password) VALUES(#{id}, #{username}, #{password});
</insert>
<update id="updateUser" parameterType="com.hefery.pojo.User">
UPDATE user SET name=#{username},password=#{password} WHERE id=#{id};
</update>
<delete id="deleteUserById" parameterType="int">
DELETE FROM user WHERE id=#{id};
</delete>
</mapper>
MyBatis核心配置
mybatis-config.xml:标签设置较为全面,重点是 mappers 映射器,还设置了 jdbc.properties 外部文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!-- configuration核心配置-->
<configuration>
<!-- 標簽順序:properties、settings、typeAliases、environments、mappers-->
<!--properties标签:优先加载外部的properties文件,使用 ${} 引用-->
<properties resource="jdbc.properties"/>
<!-- 设置 -->
<settings>
<!-- *驼峰命名转换 -->
<setting name="mapUnderscoreToCamelCase" value="true"/>
<!-- *log4j日志 -->
<setting name="logImpl" value="STDOUT_LOGGING" />
<!-- *全局性地开启或关闭所有映射器配置文件中已配置的任何缓存 -->
<setting name="cacheEnabled" value="true"/>
<!-- *延迟加载:当开启时,所有关联对象都会延迟加载。 特定关联关系中可通过设置 fetchType 属性来覆盖该项的开关状态 -->
<setting name="lazyLoadingEnabled" value="true"/>
<!-- 是否允许单个语句返回多结果集 -->
<setting name="multipleResultSetsEnabled" value="true"/>
<!-- 使用列标签代替列名 -->
<setting name="useColumnLabel" value="true"/>
<!-- 允许 JDBC 支持自动生成主键,需要数据库驱动支持。如果设置为 true,将强制使用自动生成主键-->
<setting name="useGeneratedKeys" value="false"/>
<!-- 指定 MyBatis 应如何自动映射列到字段或属性:NONE 表示关闭自动映射;PARTIAL只会自动映射没有定义嵌套结果映射的字段; FULL 会自动映射任何复杂的结果集(无论是否嵌套) -->
<setting name="autoMappingBehavior" value="PARTIAL"/>
<!-- 指定发现自动映射目标未知列(或未知属性类型)的行为:NONE: 不做任何反应;WARNING: 输出警告日志;FAILING: 映射失败 (抛出 SqlSessionException) -->
<setting name="autoMappingUnknownColumnBehavior" value="WARNING"/>
<!-- 配置默认的执行器:SIMPLE 就是普通的执行器;REUSE 执行器会重用预处理语句(PreparedStatement); BATCH 执行器不仅重用语句还会执行批量更新-->
<setting name="defaultExecutorType" value="SIMPLE"/>
<!-- 设置超时时间:决定数据库驱动等待数据库响应的秒数 -->
<setting name="defaultStatementTimeout" value="25"/>
<!-- 为驱动的结果集获取数量(fetchSize)设置一个建议值。此参数只可以在查询设置中被覆盖 -->
<setting name="defaultFetchSize" value="100"/>
<!-- 是否允许在嵌套语句中使用分页(RowBounds)。如果允许使用则设置为 false -->
<setting name="safeRowBoundsEnabled" value="false"/>
<!-- 本地缓存机制防止循环引用和加速重复的嵌套查询:默认值为 SESSION,会缓存一个会话中执行的所有查询。 若设置值为 STATEMENT,本地缓存将仅用于执行语句,对相同 SqlSession 的不同查询将不会进行缓存 -->
<setting name="localCacheScope" value="SESSION"/>
<!-- 当没有为参数指定特定的 JDBC 类型时,空值的默认 JDBC 类型 -->
<setting name="jdbcTypeForNull" value="OTHER"/>
<!-- 指定对象的哪些方法触发一次延迟加载 -->
<setting name="lazyLoadTriggerMethods" value="equals,clone,hashCode,toString"/>
</settings>
<!-- 类型別名 -->
<typeAliases>
<!-- 为 Java 类型设置一个缩写名字。 它仅用于 XML 配置,意在降低冗余的全限定类名书写 -->
<typeAlias type="com.hefery.pojo.User" alias="User" />
<!-- 指定一个包名,MyBatis 会在包名下面搜索需要的 Java Bean:
在没有注解的情况下,会使用 Bean 的首字母小写的非限定类名来作为它的别名,比如 domain.blog.Author 的别名为 author
若有注解,则别名为其注解值,在类处指定@Alias("User") public class User {...}
-->
<package name="com.hefery.pojo"/>
</typeAliases>
<!-- 环境配置 -->
<environments default="development">
<!-- 开发环境 -->
<environment id="development">
<!-- 事务管理的类型:Java的JDBC的提交和回滚设置 -->
<transactionManager type="JDBC"/>
<!-- 连接源配置DataSource:POOLED是采用连接池的方式管理数据库的连接 -->
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
<!-- 测试环境 -->
<environment id="test">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<!-- 映射器 :每个 Mapper.xml 都要在 MyBatis 核心配置文件中注册 -->
<mappers>
<mapper resource="mappers/UserMapper.xml"/>
</mappers>
</configuration>
MyBatis映射文件
select:
insert:
updae:
delete:
resultMap:
parameterMap:
sql:
include:
Mybatis的Xml映射文件和Mybatis内部数据结构之间的映射关系?
Mybatis将所有Xml配置信息都封装到All-In-One重量级对象Configuration内部。在 Xml映射⽂件中,
被解析为ParameterMap对象,其每个子元素会被解析为ParameterMapping 对象。
Mapper接口调用要求
1.Mapper接口方法名和mapper.xml中定义的每个sql的id相同
2.Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的parameterType的类型相同
3.Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同
4.Mapper.xml文件中的namespace即是mapper接口的类路径
id是否可以重复
不同的Xml映射文件,如果配置了namespace,那么id可以重复;如果没有配置namespace,那么id不能重复;毕竟namespace不是必须的,只是最佳实践而已。原因就是namespace+id是作为Map<String, MappedStatement>的key使用的,如果没有namespace,就剩下id,那么,id重复会导致数据互相覆盖。有了namespace,自然id就可以重复,namespace不同,namespace+id自然也就不同
接口绑定的实现方式
在MyBatis中任意定义接口,然后把接口里面的方法和SQL语句绑定,我们直接调用接口方法就可以
1.注解绑定,就是在接口的方法上面加上 @Select、@Update等注解,里面包含Sql语句来绑定
2.xml里面写SQL来绑定, 在这种情况下,要指定xml映射文件里面的namespace必须为接口的全路径名
Xml映射文件有Dao接口与之对应,Dao接口工作原理?Dao接口方法能否重载
Dao接口/Mapper接口,接口的全限名是映射文件中的 namespace 值,接口的方法名是映射文件中 MappedStatement 的 id 值,接口方法内的参数是传递给 SQL 的参数。Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为key值,可唯一定位一个 MappedStatement,举例:com.mybatis3.mappers.StudentDao.findStudentById,可以唯一找到namespace为com.mybatis3.mappers.StudentDao下面id =findStudentById的MappedStatement。在Mybatis中,每一个<select>、<insert>、<update>、
Mybatis是否可以映射Enum枚举类
Mybatis可以映射枚举类,不单可以映射枚举类,Mybatis可以映射任何对象到表的⼀列上。映射⽅式为⾃定义⼀个TypeHandler,实现TypeHandler的setParameter()和getResult()接⼝⽅法。TypeHandler有两个作⽤,⼀是完成从javaType⾄jdbcType的转换,⼆是完成jdbcType⾄javaType的转换,体现为setParameter()和getResult()⽅法,分别代表设置sql问号占位符参数和获取列查询结果
Mybatis分页
#{} 和 ${} 符号区别
- ${}:字符串替换。Mybatis在处理${}时,就是把${}替换成变量的值
- #{}:预编译处理。SQL的参数占位符,Mybatis处理#{}时,会将SQL中的#{}替换为?号,调用PreparedStatement的set方法,按序给SQL的 ? 号占位符设置参数值。如 ps.setInt(0, parameterValue),#{item.name} 的取值方式为使用反射从参数对象中获取 item 对象的 name 属性值,相当于 param.getItem().getName()。使用#{}可以有效的防止SQL注入,提高系统安全性
MyBatis注解开发
在 DAO 方法上使用注解,避免使用 xml 文件写 SQL,但只适用简单 SQL,复杂的语句还是 xml 比较适合
|-- 库表:user(id, name, password)
|-- 方法:
|-- List<User> getUserList(); // 查询所有 user
|-- User getUserById(int id); // 根据 id 查找 user
|-- int insertUser(User user); // 新增 user,使用 User 对象传值
|-- int updateUser(User user); // 修改 User
|-- int deleteUserById(int id); // 根据 id 删除 user
public interface UserMapper {
@Select("SELECT * FROM user")
List<User> getUserList();
// 基本类型和String要加@Param注解,引用无需添加,与#{}内容一致
@Select("SELECT * FROM user WHERE id=#{id}")
User getUserById(@Param("id") int id);
@Insert("INSERT INTO user(id, name, password) VALUES(#{id}, #{username}, #{password});")
int insertUser(User user);
// #{"POJO属性"}
@Update("UPDATE user SET name=#{username},password=#{password} WHERE id=#{id};")
int updateUser(User user);
@Delete("DELETE FROM user WHERE id=#{id};")
int deleteUserById(@Param("id") int id);
}
复杂查询
|-- 库表:
|-- teacher(id, name, tid)
|-- student(id, name)
|-- 方法:
|-- List<Student> getStudentList(); // 查询所有 student 信息,及其对应 teacher 的信息
|-- List<Student> getStudent1(); // 联合查询(子查询,较复杂)
|-- List<Student> getStudent2(); // 嵌套查询(联合嵌套,推荐)
|-- List<Teacher> getTeacherList(); // 查询所有 teacher
|-- Teacher getTeacherById(int id); // 通过 id 查询 teacher
|-- List<Teacher> getTeacher(@Param("tid") int tid); // 获取指定 tid 老师信息及该老师对应各个学生
|-- Teacher getTeacher1(@Param("tid") int tid); // 嵌套查询(联合嵌套,推荐)
|-- Teacher getTeacher2(@Param("tid") int tid); // 联合查询(子查询,较复杂)
<mapper namespace="com.hefery.dao.StudentMapper">
<!--==============================================多对一(学生:老师)==============================================-->
<!-- 1.一条SQL查出所有学生与其对应的老师 -->
<select id="getStudentList" resultType="Student">
SELECT s.id,s.name,t.name FROM student AS s, teacher AS t WHERE s.tid=t.id;
</select>
<!--
2.查询嵌套(子查询):先查所有学生,根据学生的tid查对应的老师
-->
<select id="getStudent1" resultMap="StudentAndTeacher1">
SELECT * FROM student;
</select>
<!-- property:POJO属性 column:数据库字段 -->
<resultMap id="StudentAndTeacher1" type="Student">
<!-- 简单属性 -->
<id property="id" column="id" />
<id property="name" column="name" />
<!-- 复杂属性:对象:association 集合:collection -->
<association property="teacher" column="tid" javaType="Teacher" select="getTeacherById"/>
</resultMap>
<select id="getTeacherById" resultType="Teacher">
SELECT * FROM teacher WHERE id=#{tid};
</select>
<!--
3.结果嵌套(联合嵌套,推荐)
-->
<select id="getStudent2" resultMap="StudentAndTeacher2">
SELECT s.id AS sid, s.name AS sname, t.name AS tname
FROM student AS s, teacher AS t
WHERE s.tid=t.id;
</select>
<resultMap id="StudentAndTeacher2" type="Student">
<result property="id" column="sid" />
<result property="name" column="sname" />
<association property="teacher" javaType="Teacher">
<result property="name" column="tname" />
</association>
</resultMap>
</mapper>
一对一
|-- 一对一:Order:User
|-- 需求:查询一个订单,与此同时查询出该订单所属的用户
|-- 语句:select * from orders o,user u where o.uid=u.id;
|-- 策略:<resultMap> + <result>
|-- 在 resultMap 标签使用 result 标签匹配单个字段
多对多
|-- 多对多:student:teacher
|-- 需求:查询 student 信息,在 Student POJO 添加属性 tid 表示 teacher 的 id,从而关联 student 和 teacher
|-- 语句:SELECT s.id AS sid, s.name AS sname, t.name AS tname FROM student AS s, teacher AS t WHERE s.tid=t.id;
|-- 需求:查询用户同时查询出该用户的所有角色
|-- 语句:SELECT u.*, r.*, r.id AS rid FROM user AS u LEFT JOIN user_role AS ur ON u.id=ur.user_id
|-- 策略:<resultMap> + <result> + <association>
|-- 在 resultMap 标签添加 association 标签,查询 student 信息附带的 teacher 信息
<mapper namespace="com.hefery.dao.TeacherMapper">
<select id="getTeacherList" resultType="Teacher">
SELECT * FROM teacher;
</select>
<select id="getTeacherById" resultType="Teacher">
SELECT * FROM teacher WHERE id=#{id};
</select>
<!--==============================================一对多(老师:学生)==============================================-->
<!-- 1.一条SQL获取指定tid的老师信息及该老师对应的各个学生 -->
<select id="getTeacher" resultType="Teacher">
SELECT t.id AS tid, t.name AS tnanme, s.id AS sid, s.name AS sname
FROM teacher AS t, student AS s
WHERE t.id = #{tid} AND t.id = s.tid
</select>
<!-- 结果嵌套-->
<select id="getTeacher1" resultMap="TeacherAndStudent1">
SELECT t.id AS tid, t.name AS tname, s.id AS sid, s.name AS sname
FROM teacher AS t, student AS s
WHERE t.id=#{tid} AND s.tid=t.id
</select>
<resultMap id="TeacherAndStudent1" type="Teacher">
<result property="id" column="tid"/>
<result property="name" column="tname"/>
<collection property="students" ofType="Student">
<result property="id" column="sid"/>
<result property="name" column="sname"/>
<result property="tid" column="tid"/>
</collection>
</resultMap>
<!-- 子查询 -->
<select id="getTeacher2" resultMap="TeacherAndStudent2">
SELECT id, name FROM teacher WHERE id=#{tid};
</select>
<resultMap id="TeacherAndStudent2" type="Teacher">
<collection property="students" javaType="ArrayList" ofType="Student" select="getStudentsByTeacherId" column="id"/>
</resultMap>
<select id="getStudentsByTeacherId" resultType="Student">
SELECT id, name FROM student WHERE tid=#{tid};
</select>
</mapper>
一对多
|-- 一对多:teacher:student
|-- 需求:查询 teacher 信息,在 Teacher POJI 添加列表 List<Student> students,表示该 teacher 旗下的 student
|-- 语句:SELECT t.id AS tid, t.name AS tname, s.id AS sid, s.name AS sname FROM teacher AS t, student AS s WHERE t.id=#{tid} AND s.tid=t.id
|-- 需求:查询一个用户,与此同时查询出该用户具有的订单
|-- 语句:SELECT *, o.id AS oid FROM user AS u LEFT JOIN orders AS o ON u.id=o.uid;
|-- 策略:<resultMap> + <result> + <collection>
|-- 在 resultMap 标签添加 collection 标签,查询 teacher 信息附带的 student 信息
日志设置
在 mybatis-config.xml 的 settings 标签引入 logImpl 可以设置 value 为 STDOUT_LOGGING 是控制台输出,也可设置为 LOG4J
<configuration>
<!--properties标签:优先加载外部的properties文件,使用 ${} 引用-->
<properties resource="jdbc.properties"/>
<!-- 设置 -->
<settings>
<!-- *驼峰命名转换 -->
<setting name="mapUnderscoreToCamelCase" value="true"/>
<!-- *控制台打印日志 -->
<setting name="logImpl" value="LOG4J" />
</settings>
......
</configuration>
配置 DEBUG 和 ERROR 级别的日志信息,将 DEBUG 输出到控制台和 debug.log 文件,将 ERROR 输出到 error.log 文件
# 输出优先级,即DEBUG,INFO,WARN,ERROR,FATAL
# 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,比如:%d{yyy MMM dd HH:mm:ss,SSS},输出类似:2002年10月18日 22:10:28,921
# 输出日志事件的发生位置,包括类目名、发生的线程,以及在代码中的行数。举例:Testlog4.main(TestLog4.java:10)
### 全局日志配置:将 DEBUG 级别的日志信息分别输出到 console 和 debugfile;将 ERROR 级别的日志信息分别输出到 errorfile
log4j.rootLogger = DEBUG,console,debugfile,errorfile
### 控制台输出设置
log4j.appender.console = org.apache.log4j.ConsoleAppender
log4j.appender.console.Target = System.out
log4j.appender.console.Threshold = DEBUG
log4j.appender.console.layout = org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
### 输出 DEBUG 级别以上的日志到 debug.log
log4j.appender.debugfile = org.apache.log4j.DailyRollingFileAppender
log4j.appender.debugfile.File = ./log/debug.log
log4j.appender.debugfile.MaxFileSize = 10mb
log4j.appender.debugfile.Append = true
log4j.appender.debugfile.Threshold = DEBUG
log4j.appender.debugfile.layout = org.apache.log4j.PatternLayout
log4j.appender.debugfile.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
### 输出 ERROR 级别以上的日志到 error.log
log4j.appender.errorfile = org.apache.log4j.DailyRollingFileAppender
log4j.appender.errorfile.File = ./log/error.log
log4j.appender.errorfile.Append = true
log4j.appender.errorfile.Threshold = ERROR
log4j.appender.errorfile.layout = org.apache.log4j.PatternLayout
log4j.appender.errorfile.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
### 日志输出级别
log4j.logger.org.mybatis=DEBUG
log4j.logger.java.sql=DEBUG
log4j.logger.java.sql.Statement=DEBUG
log4j.logger.java.sql.ResultSet=DEBUG
log4j.logger.java.sql.PreparedStatement=DEBUG
动态SQL
|-- 库表:blog(id, title, author, create_time, views)
|-- 方法:
|-- int addBlog(Blog blog); // 新增 blog
|-- 说明:
|-- 库表设置 id 为 varchar,工具类 IDUtils 使用 UUID 生成 id 策略
|-- 抽取 sql:
|-- 使用 sql 标签抽取公共代码 PS:不要在内使用 where 标签,一般用于抽取表字段
|-- <sql id="blog_table_columns"> id, title, author, create_time, views </sql>
|-- 使用 include 标签引用 sql 标签内容
|-- <include refid="blog_table_columns"/>
|-- 选择 if:
|-- 用于条件判断
|-- <if test="title != null">
|-- title=#{title},
|-- </if>
|-- 选择 choose (when, otherwise):
|-- 相当于 Java 的 switch-case 语句
|-- <choose>
|-- <when test="title != null">
|-- title = #{title}
|-- </when>
|-- <when test="author != null">
|-- AND author = #{author}
|-- </when>
|-- <otherwise>
|-- views = #{views}
|-- </otherwise>
|-- </choose>
|-- 条件
|-- where 基本必用,只会在子元素返回任何内容的情况下才插入 WHERE 子句
|-- set 用于 update,会动态地在行首插入 SET 关键字,并会删掉额外的逗号
|-- trim:
|-- 循环 foreach:
|-- 对集合进行遍历(尤其是在构建 IN 条件语句的时候)
|-- <foreach item="item" index="index" collection="list" open="(" separator="," close=")">
|-- #{item}
|-- </foreach>
|-- 参数说明:item(集合中的元素)、index(item下标,可不要)、collection(集合)、open(集合开头符)、separator(元素分隔符)、close(集合结束符)
|-- 遍历结果:( item1, item2, ... )
<mapper namespace="com.hefery.dao.BlogMapper">
<sql id="blog_table_columns">
id, title, author, create_time, views
</sql>
<insert id="addBlog" parameterType="Blog">
INSERT INTO blog(<include refid="blog_table_columns"/>) VALUES (#{id}, #{title}, #{author}, #{createTime}, #{views})
</insert>
<select id="queryBlogListByIF" parameterType="map" resultType="Blog">
SELECT * FROM blog
<where>
<if test="title != null">
title = #{title}
</if>
<if test="author != null">
AND author = #{author}
</if>
</where>
</select>
<select id="queryBlogListByChoose" parameterType="map" resultType="Blog">
SELECT * FROM blog
<where>
<choose>
<when test="title != null">
title = #{title}
</when>
<when test="author != null">
AND author = #{author}
</when>
<otherwise>
views = #{views}
</otherwise>
</choose>
</where>
</select>
<update id="updateBlog" parameterType="map">
UPDATE blog
<set>
<if test="title != null">
title=#{title},
</if>
<if test="author != null">
author=#{author},
</if>
<if test="createTime != null">
createTime=#{createTime},
</if>
<if test="views != null">
views=#{views}
</if>
</set>
WHERE id=#{id}
</update>
<select id="queryBlogListByForeach" parameterType="map" resultType="Blog">
SELECT <include refid="blog_table_columns"></include> FROM blog
<where>
<foreach collection="ids" item="id" index="index" open="and (" separator="or" close=")">
id = #{id}
</foreach>
</where>
</select>
</mapper>
动态SQL执行原理
Mybatis动态sql可以在Xm 映射⽂件内,以标签的形式编写动态sql,完成逻辑判断和动态拼接sql的功能,
提供了9种动态sql标签:trim|where|set|foreach|if|choose|when|otherwise|bind
执⾏原理为,使⽤OGNL从sql参数对象中计算表达式的值,根据表达式的值动态拼接sql,以此来完成动态sql的功能
MyBatis缓存
缓存本质:存储在内存的临时数据
作用:减少和数据库交互的次数,减少系统开销,提高系统效率。将用户经常查询的数据放到缓存中,用户去查数据就不用直接从数据库查,从缓存中查询,提高查询效率,解决高并发系统的性能问题
对象:经常查询并且不经常改变的数据
|-- 一级缓存:默认开启,SqlSession 级别的缓存,缓存数据随着 CRUD 方法的 sqlSession.close() 而被清除
|-- 二级缓存:默认关闭,namespace 级别的缓存,定义了缓存接口 Cache 可自定义 MyBatis 二级缓存
|-- 工作机制:
|-- 一个会话查询一条数据,该条数据就会被存入一级缓存,如果结束会话,一级缓存也就失效
|-- 开启二级缓存,关闭 sqlSession 会话,sqlSession 的一级缓存会存到二级缓存中
|-- 不同的 Mapper 查询出的数据缓存在自己对于的缓存(map)中
|-- 缓存清除策略:
|-- LRU :最近最少使用,清除最长时间不被使用的对象
|-- FIFO:先进先出,按对象进入缓存的顺序来清除
|-- SOFT:软引用,基于垃圾回收期状态和软引用规则移除对象
|-- WEAK:弱引用,基于垃圾回收期状态和弱引用规则移除对象
|-- 开启步骤:
|-- 1.在 mybatis-config.xml 的 settings 标签显式开启全局缓存(尽管默认开启)
|-- <setting name="cacheEnabled" value="true"/>
|-- 2.在 XXXMapper.xml 任意位置添加 </cache>,也可配置参数
|-- <cache
|-- eviction="FIFO" // 缓存策略(LRU、FIFO、SOFT、WEAK)
|-- flushInterval="60000" // 缓存间隔:60s
|-- size="512" // 最多可存储对象或列表为 512 个引用
|-- readOnly="true" // 返回对象为只读
|-- />
|-- 存在隐患:
|-- 需要将实体类序列化,否则会报错:public class User implements Serializable { ... }
|-- 查询顺序:用户 -> 二级缓存 -> 一级缓存 -> 数据库
开启二级缓存
|-- 库表:user(id, name, password)
|-- 方法:
|-- User queryUserById(@Param("id") int id); // 根据 id 查找 user
|-- 说明:
|-- 映射语句文件中所有的 select 语句的结果将被缓存
|-- 缓存失效:
|-- 映射语句文件中所有的 insert、update 和 delete 语句会刷新缓存
|-- 查询不同的数据
|-- 查询不同的 Mapper.xml
|-- 手动清理缓存
|-- 缓存使用最近最少使用算法(LUR,Least Recently Used)清除不需要的缓存
|-- 缓存不会定时刷新,没有刷新间隔
<configuration>
<!-- 標簽順序:properties、settings、typeAliases、environments、mappers-->
<!--properties标签:优先加载外部的properties文件,使用 ${} 引用-->
<properties resource="jdbc.properties"/>
<!-- 设置 -->
<settings>
<!-- *驼峰命名转换 -->
<setting name="mapUnderscoreToCamelCase" value="true"/>
<!-- *开启日志 -->
<setting name="logImpl" value="STDOUT_LOGGING" />
<!-- *显式开启全局缓存 -->
<setting name="cacheEnabled" value="true"/>
</settings>
</configuration>
<mapper namespace="com.hefery.dao.UserMapper">
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"
/>
<select id="queryUserById" parameterType="int" resultType="com.hefery.pojo.User">
SELECT * FROM user WHERE id=#{id};
</select>
<update id="updateUser" parameterType="User">
UPDATE user SET name=#{username}, password=#{password} WHERE id=#{id}
</update>
</mapper>
给我五分钟,带你彻底掌握 MyBatis 缓存的工作原理-阿里云开发者社区 (aliyun.com)
Q&A
SQL注入是什么?为什么预编译可以防止SQL注入?
通过在Web表单恶意输入SQL得到存在安全漏洞的网站上的数据库,而不是按照设计者意图去执行SQL语句
针对程序员编写时的疏忽,通过SQL语句,实现无账号登录,甚至篡改数据库
举例:当执行的sql为 select * from user where username = “admin” or “a”=“a”时,SQL恒成立
String sql = "select * from user_table where username=' "+userName+" ' and password=' "+password+" '";
-- 当输入了上面的用户名和密码,上面的SQL语句变成:
SELECT * FROM user_table WHERE username='’or 1 = 1 -- and password='’
-- 条件后面username=”or 1=1 用户名等于 ” 或1=1 那么这个条件一定会成功
-- 后面加两个-,这意味着注释,它将后面的语句注释,让他们不起作用,这样语句永远都--能正确执行,用户轻易骗过系统,获取合法身份
SQL注入的根本原因:SQL预编译,Mybatis里用#{}来避免
防止SQL注入的方式:
- 预编译语句:select * from user where username = ?,SQL语义不会发生改变,SQL中变量用 ?
表示,即使传递参数时为“admin or ‘a’= ‘a’”,也会把这整体当做一个字符创去查询 - Mybatis框架中的 mapper 方式中的 #{} 也能很大程度的防止SQL注入(${}无法防止SQL注入)
SQL预编译
预编译语句:SQL语句中的值用占位符替代(Prepared Statements或Parameterized Statements)
一条SQL在DB接收到最终执行完毕返回可以分为下面三个过程
- 词法和语义解析
- 优化SQL语句,制定执行计划
- 执行并返回结果
优势:一次编译、多次运行,省去了解析优化等过程;此外预编译语句能防止SQL注入
简述Mybatis的插件运行原理,以及如何编写⼀个插件
Mybatis仅可以编写针对ParameterHandler、ResultSetHandler、StatementHandler、Executor这4种接⼝的插件,使⽤JDK的动态代理,为需要拦截的接⼝⽣成代理对象以实现接口方法拦截功能,每当执⾏这4种接⼝对象的⽅法时,会进⼊拦截⽅法,具体就是InvocationHandler的invoke方法。当然,只会拦截那些你指定需要拦截的⽅法。实现Mybatis的Interceptor接⼝并复写intercept方法,然后在给插件编写注解,指定要拦截哪⼀个接⼝的哪些方法即可,记住,别忘了在配置文件中配置你编写的插件