
数据迁移—SQL Server数据迁移至MySQL
需求背景
项目二期上线许久,要关闭一期的使用,但是数据要迁移到二期。二期为了更好地兼容一期的重要内容,专门设置了一个模块,用于查询一期的数据
模块的开发这里不多说,项目架构和业务都有不同,重要是总结下一期数据导到二期的流程和注意事项
迁移步骤
一期数据库用的是 SQL Server,服务器还是 Windows
最初的想法:利用 SELECT 语句将查询结果导到 Excel,再从服务器把导出的 Excel 拉到本地,使用 Navicat 导到二期 MySQL
-
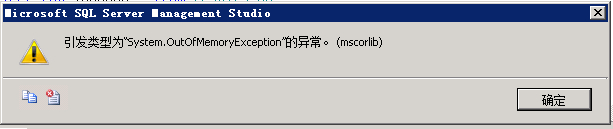
一次查询的数据过多,查询结果右键选中“连同标题一起复制”报错(数据库中的 OOM),即使从数据库 copy 不报错,再粘贴到 Excel 也可能出现问题。因此适合少量数据,一张 Excel 能轻松导完,面对数据量上到一定程度,这样操作极大地损耗时间和精力。而且这样还有个很严重的问题需要处理,就是 Excel 中的 NULL,从 SQL Server 导出到 Excel 的 NULL 是 String 类型,就是说如果不加处理,直接用 Navicat 导到 MySQL,那这个 String 类型的 NULL 也会以字符串的形式保存在数据库中,这样显然是有问题的,对于这个问题的处理就是先在 Excel 将 NULL 全部以单元格形式替换为空串,再在 Navicat 导入时设置将空串设置为 NULL
-
查询结果右键选中“将结果另存为...”导出至 CSV 会出现中文乱码,而且不带标题(字段名称),这个会影响后续 Navicat 导入,会根据 Excel 首行的标题进行导入的字段匹配
针对上述两个问题,当时没想出好方案,基本上是一次查询能够承载的数据量,比如说 10w,然后将查询结果右键选中“连同标题一起复制”粘贴到 Excel。字段多的连 10w 都不能,只能是 5w 左右,记得有张主表在 MySQL 字段多得已经不能再添加新的字段了
为了保证数据导出的完整性,又因为表没有可分组排序的字段可用,只能使用 top 和 not in,特别注意一定要使用 ID 排序。这条 SQL 的意思也很简单,就是把 ID 排完序的前 7880000 条数据不要,取后 100000 条,下一次查询就是排除 7980000 条数据
select top 100000 * from table_name ad
where ad.ID not in (
select top 7880000 ID from table_name order by ID
)
order by ID
当我面对一张 7145.4136w 的表时,我开始犹豫了,我大概算了一下,这张表共 100+ 个字段,一次最大能够复制粘贴 10w 条数据,那么要导出 715 个 Excel 文件,周末没了,我也没了……后来我极尽巧思,找到一个我认为的最佳实践:创建视图,Excel 使用外部数据源。每次大概导 100w 条数据,导出的单个 Excel 也就 150 MB不到,而且 Excel 的 NULL 字符串无需再处理,已经是空串
语句还是那个语句,就是以视图的形式使用,运行很快(比起直接查询简直节约了不知道多少时间),
创建视图 vw_results_72
CREATE VIEW vw_results_72
AS
select top 1000000 * from table_name ad
where ad.ID not in (
select top 71000000 ID from table_name order by ID
)
order by ID
在 Excel 使用外部数据源:数据 --> 自其他来源 --> SQL Server
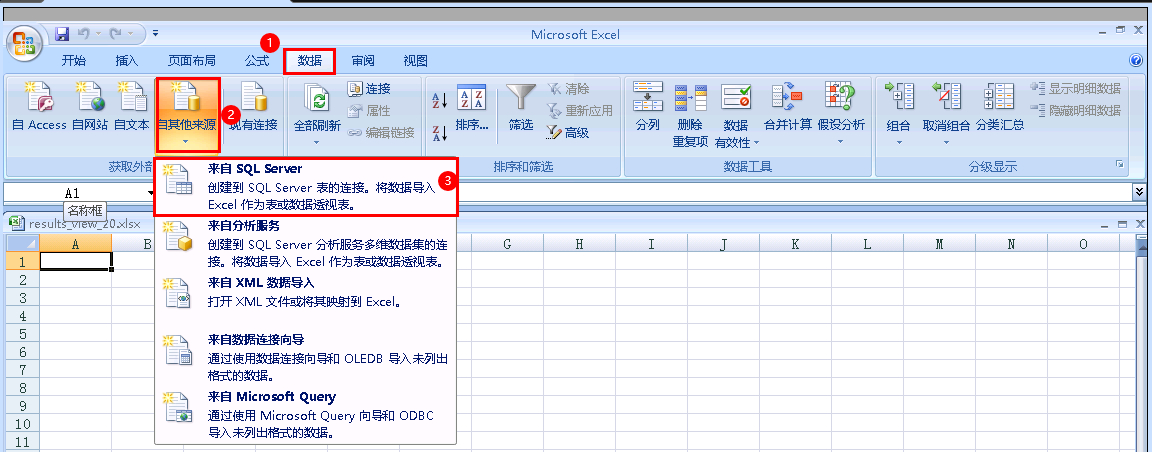
填写连接信息
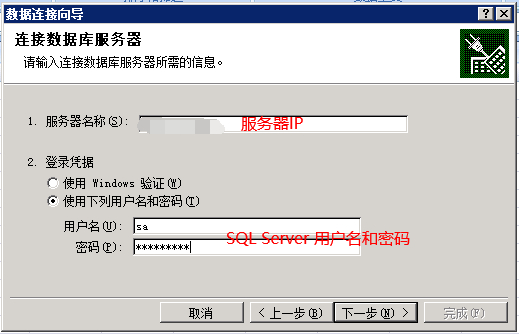
选择数据库和视图
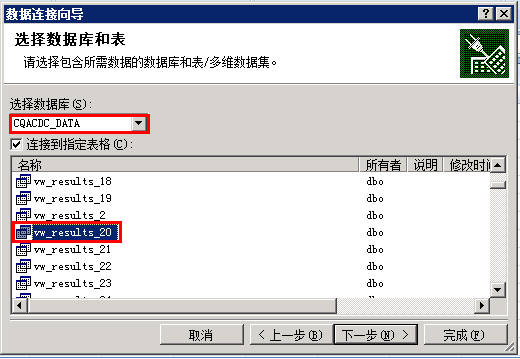
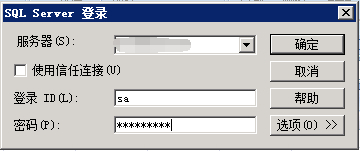
一直下一步,最后会有个登陆,输入下密码即可
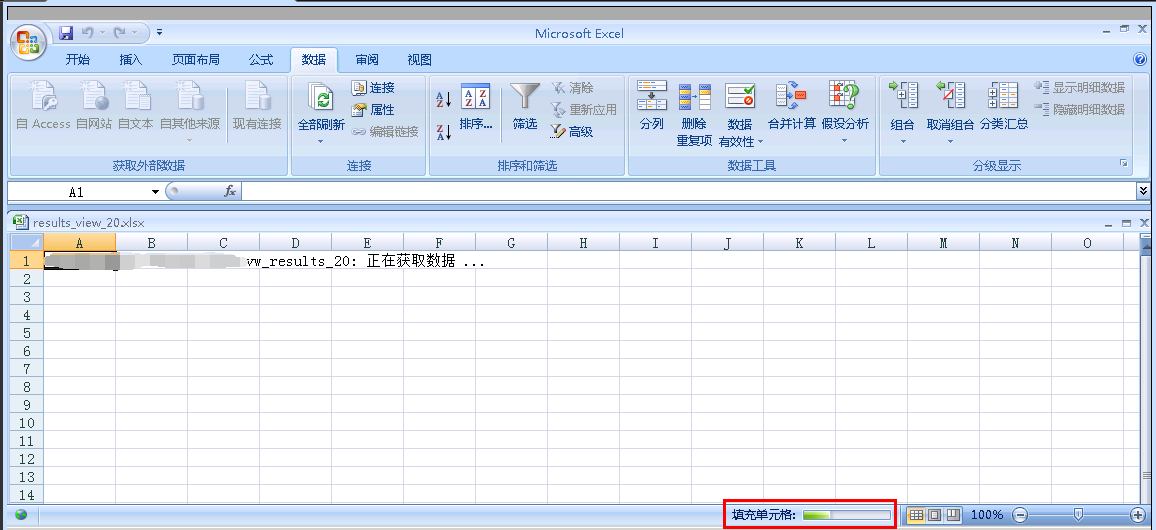
然后就是等待数据的录入,保存下就 OK 了
反思复盘
因为之前一直没这方面经验,所以需要时间去试错,但是在不断尝试的过程中,我明白了一个道理:有些累源于无知